
Your brand appears in ChatGPT answers. It shows up in Perplexity citations. You’ve built the dashboards, pulled the reports, and called it covered.
But when a senior engineer at a Fortune 500 company opens Claude and asks which platform best fits their stack, your brand might not exist at all.
That’s not a tracking failure. That’s an architecture problem.
Claude Doesn’t Search Like the Others
Most marketers treat AI visibility as one metric across one pool of platforms. That assumption is costing them placements they can’t see.
Perplexity is a retrieval engine. It crawls the live web in real time, indexes sources, and surfaces citations for every query. ChatGPT runs a hybrid model, blending its training weights with optional web search. Both systems reward recent, indexed content.
Claude operates differently. Its brand recommendations originate primarily from training data and its internal weights, not from a real-time web crawl. While newer versions like Claude Opus 4.7 have integrated optional search, the model exhibits a persistent “training data bias”: when retrieved web content conflicts with internal training memory, Claude tends to default to what it learned during pre-training.
The practical consequence: a brand that launched a new product line last quarter may not see that positioning reflected in Claude’s answers for 6 to 18 months.
That’s not a bug. It’s the architecture.
The 3 Signals That Shape Claude AI Brand Visibility
Visibility on Claude isn’t a ranking. It’s a probability. The model assesses the likelihood that your brand is the most helpful, honest, and reliable answer to a specific user intent. Three signals drive that assessment.
Training Data Density and Entity Authority
The most powerful signal is how frequently your brand appeared in high-authority datasets before the model’s knowledge cutoff. Technical documentation, academic papers, developer forums like Stack Overflow, GitHub citations, and industry-standard publications all carry significant weight. Standard blog posts, comparatively, carry far less.
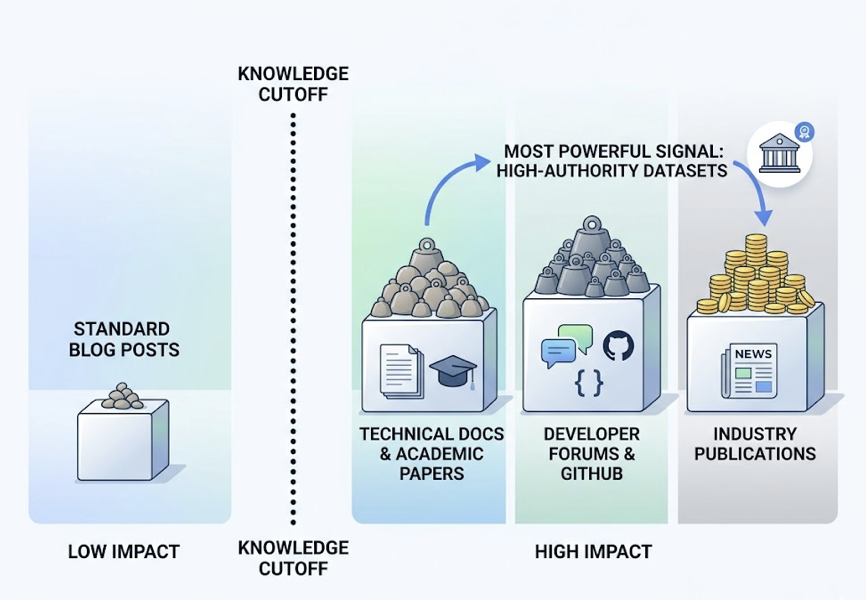
This creates a winner-take-all dynamic. Once a brand is encoded as the default reference in Claude’s weights for a given category, it gets retrieved consistently across thousands of diverse prompts. Brands that haven’t built that footprint in authoritative sources are often invisible, even if they rank well on Google.
Semantic Proximity in Context Windows
Claude can process up to 200,000 tokens in standard tiers and 500,000+ tokens in Enterprise versions. When a user uploads a long RFP, technical specification, or internal document, Claude evaluates brands based on how well their identity maps to the specific problems described in that context.
This is where brand naming creates real risk. For brands with common-noun names, uncontextualized queries return near-zero recognition. The model defaults to the dictionary definition. When category context is added, recognition can jump to 100%. Consistently pairing your brand name with specific technical “scenario words” — think “SOC 2 compliant CRM” or “Kubernetes-native observability” — is what teaches Claude to disambiguate your entity from general language.
Constitutional Alignment and Sentiment Signal
Anthropic trained Claude using a “Constitutional AI” methodology, embedding a set of ethical guidelines derived from sources like the UN Declaration of Human Rights. These principles function as a narrative filter. Claude is intentionally more measured in its recommendations than ChatGPT. It phrases suggestions with qualifiers like “Popular options include…” and avoids overconfident endorsements.
For brands, the implication is direct: Claude doesn’t just track positive or negative sentiment. It assesses your brand’s alignment with its safety and reliability guidelines. A brand associated with data privacy controversies or factual inconsistencies in its training data may be excluded from recommendations entirely.
Claude vs. ChatGPT vs. Perplexity: The Structural Gap
Understanding the difference between these platforms requires comparing them at the architecture level, not just the output level.
| Dimension | ChatGPT (GPT-5.4) | Perplexity (Sonar) | Claude (Opus 4.7) |
|---|---|---|---|
| Core function | Conversational task engine | Real-time search engine | Analysis-first assistant |
| Data sourcing | Hybrid: training + search | Real-time web index | Training data (search optional) |
| Trust mechanism | Consistency and usability | Citations and verifiability | Depth and interpretability |
| Visibility logic | Commercial consensus | Search ranking and authority | Technical E-E-A-T and reasoning |
| Update frequency | 6-12 weeks | Near real-time | 6-18 months |
| Citation bias | Established sources | Democratic, source-agnostic | Conservative, technical |
The update frequency row is where most marketing teams underestimate the risk. A content strategy built for ChatGPT’s 6-to-12-week refresh cycle will miss Claude’s 6-to-18-month training window almost entirely. The playbooks aren’t interchangeable.
Why Only Tracking ChatGPT Leaves a Revenue Gap
Claude holds a 32% share of the enterprise AI assistant market and a 42% share of the code generation market. 70% of Fortune 100 companies have integrated it into business operations.
That user base skews toward decision-makers: CTOs, developers, researchers, and analysts who use Claude specifically for deep due diligence, not casual browsing.
Here’s where the gap gets costly. Research across 50 B2B SaaS brands found that Claude mentions only 88% of tested brands, compared to 100% for ChatGPT and Gemini in identical prompt sets. Only 12% of sources cited by ChatGPT, Perplexity, and Claude overlap. A brand that’s the category leader in ChatGPT’s mainstream consensus can be entirely absent from Claude’s technical reasoning pool.
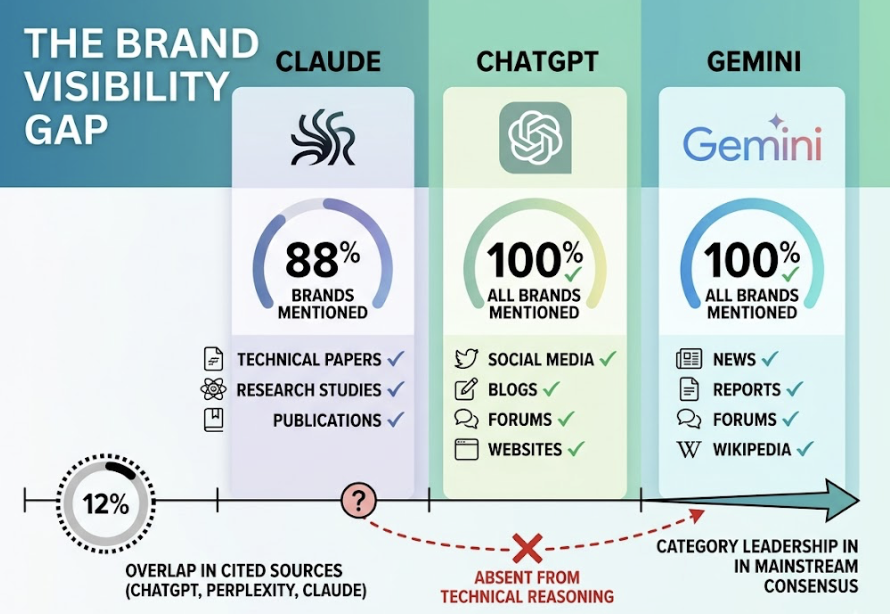
The buying journey makes this concrete. A procurement team might use ChatGPT for an initial category overview, then switch to Claude to analyze 100 pages of vendor documentation before making a final decision. If Claude doesn’t recognize your brand’s authority in that analytical phase, you’re eliminated before a human even picks up the phone.
That’s the Claude gap: invisible in the platform where enterprise decisions actually get made.
Measuring Claude AI Brand Visibility
Traditional SEO metrics, clicks, impressions, rankings, don’t transfer to the generative era. Claude operates as a zero-click intermediary. You need a different measurement framework.
The core KPIs for Claude visibility tracking:
| Metric | What It Measures |
|---|---|
| Brand Visibility Score (BVS) | Composite of mention frequency, placement, and sentiment |
| Citation Frequency | Percentage of prompts where Claude links to your content |
| Brand Mention Rate | How often your brand name appears, with or without a citation |
| Share of Model (SoM) | Your mentions relative to all category competitors |
| Sentiment Velocity | Direction of tone trends over time |
Tracking these metrics accurately requires what researchers call “Synthetic Probing”: running massive prompt matrices to simulate thousands of diverse user intents, not just manually checking a handful of queries. Claude’s output for any single prompt is stochastic. Its response to “What’s the best CRM for a fintech firm on AWS?” may vary between sessions. Statistically significant visibility data requires scale.
This is where platforms like Topify change the picture. Topify runs large-scale prompt matrices across AI platforms including ChatGPT, Gemini, Perplexity, and Claude, calculating a statistically significant Share of Model from thousands of variations per intent. It surfaces “Invisibility Gaps”: specific query scenarios where your brand is omitted despite having a relevant product. Instead of guessing where you’re missing, you get a map.
Topify tracks seven key metrics: visibility, sentiment, position, volume, mentions, intent, and CVR (Conversion Visibility Rate), unified in a single dashboard across platforms. For teams that need to make a case for Claude-specific investment, it’s the difference between anecdote and evidence.
Building a Claude Visibility Strategy That Actually Works
Fixing Claude AI brand visibility isn’t a quick optimization task. It’s a 6-to-18-month content program with three structural components.
Information Density and Technical Authority
Claude’s retrieval layer prioritizes content with a high ratio of unique facts to total word count. The practical implication: API documentation, integration guides, security whitepapers, and developer tutorials matter far more than optimized marketing copy. Content should lead with direct answers in the first 150 words, use clear headings, and follow a “premise-evidence-conclusion” structure that an LLM can parse and cite efficiently.
The Digital Cushion for Sentiment Management
Claude’s sentiment is shaped by its entire training corpus. A single negative piece on a high-authority site like Reddit can have a disproportionate impact on its recommendations. When Topify or similar tools detect a Sentiment Velocity decline, the response is to publish 10-to-15 fact-dense, high-authority articles across owned, earned, and industry channels that directly address the specific critique with data. Over time, as Claude’s knowledge refreshes, those authoritative sources dilute the negative signal.
Entity Disambiguation at Scale
Never vary your brand name in technical contexts. Use JSON-LD schema markup (FAQPage, Product, Review) to explicitly define your entity’s relationship to its category. Ensure your brand name consistently appears alongside specific technical scenario words in all authoritative content.
Done consistently, these three tracks build a content footprint that Claude recognizes as authoritative before the next major training cycle.
Conclusion
Claude is not another version of ChatGPT. It’s a separate platform with its own retrieval logic, its own trust signals, and its own user base: the developers, researchers, and enterprise decision-makers who make the final call on vendor selection.
The brands establishing a dense content footprint in authoritative sources right now will enjoy what amounts to default authority in Claude’s next training cycle. Their competitors, still optimizing exclusively for real-time search ranking, will remain invisible in the platform where the highest-value decisions are made.
That’s not a prediction. It’s already happening. The question is which side of that gap you’re on.
FAQ
Does Claude AI update brand information in real time?
Not typically. Claude primarily relies on internal training data with specific knowledge cutoffs, January 2026 for Claude Opus 4.7. While it can use web search for specific queries, research shows that when retrieved web data conflicts with training memory, Claude often defaults to its older internal associations. Correcting outdated brand positioning requires a sustained 6-to-18-month content strategy.
Is Claude brand visibility harder to measure than Perplexity?
Yes. Perplexity provides deterministic citation links for every answer, making it partially compatible with traditional tracking. Claude is a reasoning engine that often synthesizes without citations, or with conservative sourcing. Accurate measurement requires probabilistic tracking at scale: running thousands of prompt variations to calculate a statistically significant visibility rate, since any individual prompt response can vary.
Should I track Claude separately from other AI platforms?
Yes. Research shows only a 12% overlap between the sources cited by ChatGPT, Perplexity, and Claude. A brand that leads in ChatGPT’s commercial consensus pool may be entirely absent from Claude’s technical reasoning responses. Given that Claude is the preferred tool for enterprise decision-makers and developers, treating it as a separate tracking channel isn’t optional for B2B brands.

