
Track how ChatGPT and Perplexity mention your brand — without letting API costs spiral out of control.
You set up an AI monitoring script. It runs. Two weeks later, the API invoice arrives and the number is three times what you budgeted.
That’s not a freak accident. It’s the default outcome of applying traditional SEO monitoring logic to a system that charges by the token. The math is punishing in ways that aren’t obvious until you’re already in the hole.
Here’s how to track brand visibility across ChatGPT and Perplexity without burning your token budget — and what that actually looks like in practice.
Your Token Bill Spikes Faster Than You Think
Most teams underestimate AI monitoring costs because they calculate against a single query. The real cost multiplies quickly once you account for how LLM-based monitoring actually works.
Large language models are probabilistic. The same prompt doesn’t return the same answer twice. To get statistically reliable visibility data, you need multiple samples per prompt — typically three to five runs to establish a baseline. That sampling requirement alone doubles or triples your raw token count before you’ve even optimized anything.
Then there’s the system prompt problem. Every API call carries your system instructions. A system prompt that starts at 500 tokens tends to grow — added context, extra constraints, few-shot examples — and quickly balloons to 1,800 tokens or more. For a monitoring system running 5,000 calls a day, that bloat costs tens of thousands of dollars a year in pure overhead. The queries haven’t changed. The instructions are just getting heavier.
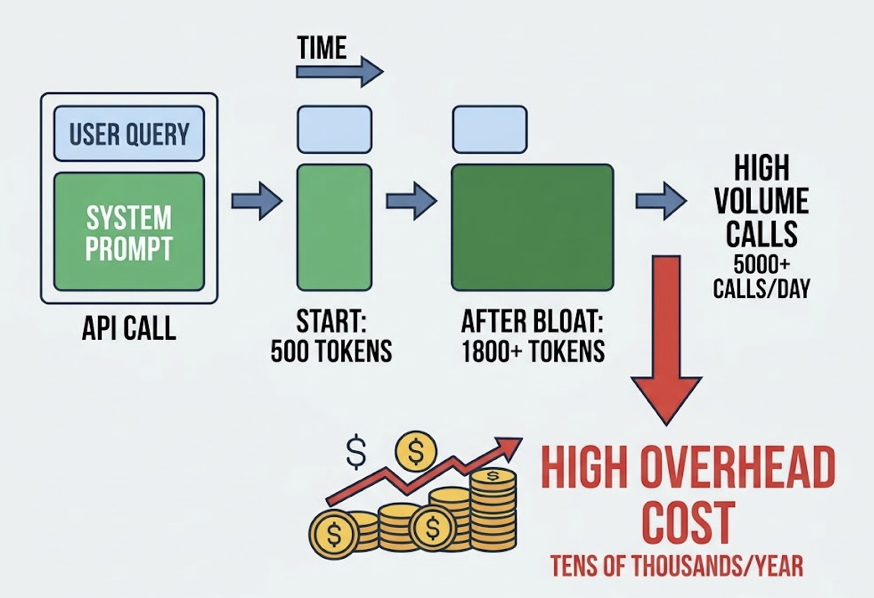
Add cross-platform tracking and the pressure compounds. ChatGPT and Perplexity index differently: Perplexity pulls from real-time web searches, Reddit threads, and review sites like G2. ChatGPT leans on its training corpus and high-authority licensed content. Because their ecosystems diverge, most DIY systems run full-volume scans on both platforms independently — which effectively doubles your spend without doubling your insight.
Most Teams Are Querying AI the Expensive Way
The “spray and pray” approach works in deterministic search. In token-billed LLMs, it destroys budgets.
Here’s how it typically plays out: a team wants to track a cloud services brand, so they build queries for every long-tail variation they can think of — “best cloud storage for small businesses,” “affordable cloud servers,” “cloud services with auto backup” — and run each one as a separate API call. These queries overlap heavily in semantic space. The model surfaces similar brand recommendations across all of them. You’re paying for redundant signal.
Uncompressed tool definitions and verbose JSON schemas compound the waste. Research on production LLM systems shows that poorly structured outputs — where you’re requesting a full narrative response instead of a compact structured extract — can inflate output token spend by 70% or more compared to format-constrained alternatives.
The cross-platform mirroring problem is just as costly. If a brand has 30% mention rate on Perplexity but near-zero on ChatGPT, running identical query volumes on both platforms makes no economic sense. Most DIY scripts don’t account for this asymmetry. They mirror queries across platforms regardless of where signal actually exists.
That’s the gap between a scraping script and a monitoring architecture.
5 Ways to Slash Token Usage Without Losing Coverage
1. Prioritize High-Signal Prompts Over Full-Keyword Sweeps
You don’t need to track 500 prompts to understand your brand’s AI visibility. You need to track the right 50.
The goal is identifying which queries actually sit on your customers’ decision path — the moments where AI recommendations influence purchase or evaluation behavior. Research on AI monitoring systems indicates that tracking the top 20% of high-intent queries covers roughly 80% of the brand visibility conversion points in the AI ecosystem.
Start by mapping your customer’s decision journey, then identify the prompts that correspond to each stage: awareness, comparison, and selection. That’s your core prompt library. Everything else is optional depth.
2. Use Response Sampling Instead of Full-Text Capture
You don’t need a 600-word AI response to know whether your brand was mentioned.
Forcing structured, minimal output — brand name, ranking position, sentiment score — through constrained prompt formatting can cut output token consumption by more than 70% compared to open-ended responses. For routine daily baseline checks, this lightweight approach gives you enough signal to detect trends without paying to generate paragraphs of context you won’t read.
Reserve full-text capture for high-signal events: a competitor spike, a sentiment shift, a new prompt category performing unexpectedly.
3. Use Batch Processing for Non-Urgent Monitoring Tasks
For weekly audits, competitor share analysis, or historical trend tracking, real-time API calls are the wrong tool.
OpenAI’s Batch API and equivalent batch processing options from other providers typically offer 50% price reductions in exchange for delayed responses, usually within 24 hours. The trade-off is almost always worth it for anything that isn’t crisis monitoring.
| Processing Mode | Cost | Best For |
|---|---|---|
| Real-time API | 100% (standard price) | Crisis PR, breaking sentiment shifts |
| Batch API | 50% (discounted) | Weekly visibility reports, audits |
| Utility model routing (Nano/Mini) | 10–20% | Basic mention detection, initial filtering |
Mapping your query types to the right processing tier — before you build the system, not after — is one of the highest-leverage architectural decisions you can make.
4. Set Visibility Thresholds to Trigger Queries On Demand
Not all monitoring needs to run on a fixed schedule. A smarter approach uses a tiered trigger system.
Run lightweight, low-cost scans continuously using utility models (GPT-5.4-nano or equivalent). Reserve expensive high-fidelity analysis for threshold events — for example, when a competitor’s mention rate on Perplexity spikes more than 15% in a single day, or when brand sentiment drops below a defined floor. That triggers a deeper query cycle using a more capable model.
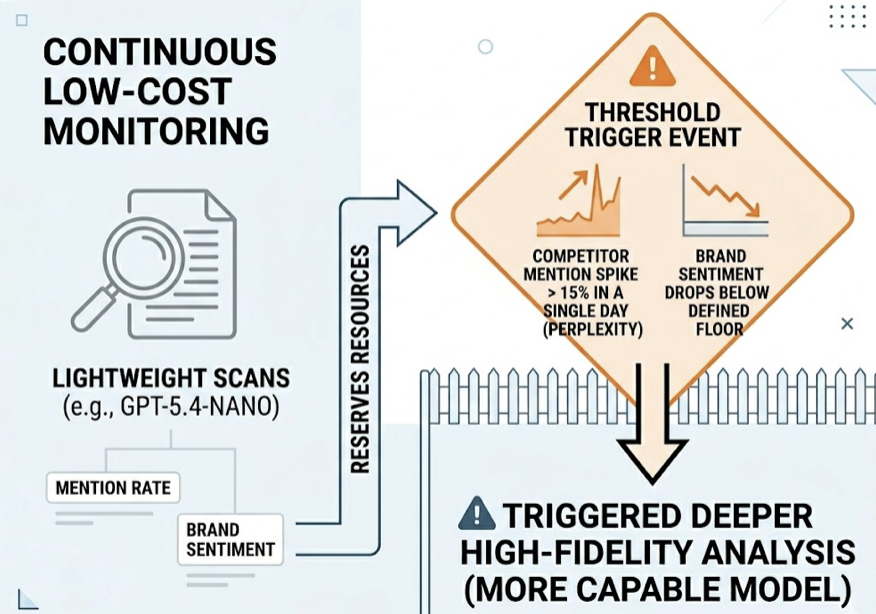
This alarm-system approach keeps your baseline spend low while ensuring you don’t miss the moments that actually matter. Most brands don’t need hourly deep analysis. They need reliable detection of anomalies and the capacity to respond fast when they appear.
5. Standardize Prompt Structure and Implement Caching
Prompt caching allows you to store stable system instructions and background context so they aren’t re-billed on every API call. Providers including Anthropic and OpenAI offer caching discounts of up to 90% on repeated prompt segments.
Pairing caching with a compact output format — structured text fields instead of verbose JSON schemas — reduces structural token waste by 30% to 60%. The savings compound over time. A monitoring system that runs thousands of queries per month accumulates meaningful cost reductions from these two optimizations alone, without any change to what you’re actually measuring.
What Efficient Tracking Looks Like in Practice
Numbers are clearer than principles, so here’s a concrete example.
Take a mid-sized cloud services company running 10,000 cross-platform queries per month with a DIY script. At standard API rates using a frontier model with no optimization, monthly API spend lands around $1,200. The system catches brand mentions but struggles with accuracy — hallucinations aren’t filtered, competitor tracking is limited to three names, and the prompt architecture is bloated.
After restructuring with a three-layer approach — nano model for daily full-sweep detection, batch API for deep analysis on flagged prompts, and prompt caching for system instructions — the same brand coverage costs $480 per month. That’s a 60% reduction. Competitor tracking expands from three to ten names. Brand coverage accuracy improves from 85% to 98% because multi-step verification filters out hallucinated mentions.
Less spend, broader coverage, higher accuracy.
That’s not a theoretical outcome. It’s the direct result of matching query type to processing mode and eliminating structural redundancy.
When DIY Stops Making Financial Sense
Token spend is only part of the cost. Once you factor in everything required to build and maintain a production-grade monitoring system, the economics shift.
Building a monitoring pipeline that handles API connection management, cost observability, output validation, and prompt versioning typically consumes 80% of an engineering team’s time on infrastructure — time not spent on anything that generates revenue. AI engineers command 30% to 50% salary premiums over traditional DevOps. Meeting GDPR and SOC2 compliance standards for data storage and processing adds $50,000 to $100,000 in annual overhead for most organizations.
Then there’s the fragility problem. OpenAI and Anthropic release model and pricing changes nearly every quarter. Custom scripts built against one API version regularly break on the next, generating constant maintenance cycles that accumulate into significant annual engineering cost.
None of these costs appear in a token bill. All of them appear in a P&L.
A purpose-built platform doesn’t just reduce API overhead. It eliminates the infrastructure maintenance burden, the compliance exposure, and the engineering distraction — and it handles edge cases that a script simply can’t, like cross-model context reuse and normalized sentiment scoring across different LLM output formats.
How Topify Tracks AI Brand Visibility Without the Token Overhead
Topify was designed around coverage efficiency rather than query volume. The architecture eliminates redundant token spending at the structural level, before a single API call goes out.
The platform’s High-Value Prompt Discovery engine uses semantic clustering of real user search behavior to generate a compact, full-funnel prompt set for each brand. Instead of asking you to input hundreds of keywords, it identifies the queries that actually drive brand recommendations — from initial awareness through competitive evaluation — and builds a prompt library optimized to minimize input token redundancy.
Topify’s cross-platform tracking uses a single query cycle to capture visibility data across ChatGPT, Perplexity, Gemini, and other major AI platforms. Where DIY systems run separate full-volume scans per platform, Topify’s architecture reuses context across platforms and applies intelligent routing — directing queries to Perplexity when real-time web search signal is needed, to ChatGPT when reasoning-based recommendations are the target. That cross-model efficiency translates directly to lower per-insight cost.
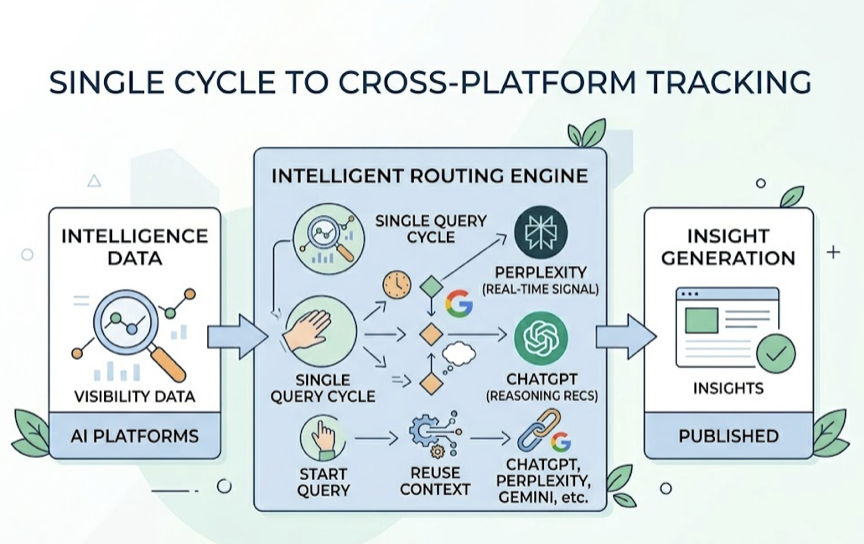
A few other structural advantages worth noting:
Unified sentiment scoring normalizes output from different models onto a single scale (–100 to +100), eliminating the token overhead of running separate sentiment analysis pipelines per platform.
Source fingerprinting means that when multiple AI platforms cite the same web page, Topify parses it once rather than billing for redundant retrieval and preprocessing.
Dynamic sampling frequency adjusts automatically based on brand activity — running lightweight checks during quiet periods and ramping up precision during PR events or competitive spikes.
For teams on the Basic plan at $99 per month, that architecture covers 100 prompts and 9,000 AI answer analyses across ChatGPT, Perplexity, and AI Overviews — without requiring you to build or maintain any of the underlying infrastructure.
Conclusion
Token costs in AI brand monitoring aren’t a billing quirk. They’re the direct result of applying high-volume, undifferentiated query logic to a system that charges per word generated.
The fix isn’t spending less on monitoring. It’s spending more precisely. High-signal prompt selection, response format constraints, batch processing, threshold-triggered analysis, and prompt caching each reduce waste without reducing coverage. Together, they typically cut token spend by 50% to 60% while improving data quality.
For teams tracking more than a handful of prompts across multiple platforms, rebuilding that efficiency layer from scratch is rarely the highest-value use of engineering time. A platform with the optimization logic already built in changes the economics entirely.
Brand visibility in AI search is becoming a core growth channel. The question isn’t whether to track it. It’s whether you’re doing it in a way that compounds over time — or one that quietly drains your budget while you’re looking somewhere else.
FAQ
Why is my brand visible on Perplexity but invisible on ChatGPT?
The two platforms index differently. Perplexity relies on real-time web search and pulls from recent blog posts, Reddit discussions, and press releases. ChatGPT’s responses reflect its training corpus and tend to favor long-established domain authority. A brand that’s been publishing actively for six months might show up prominently in Perplexity while remaining largely absent from ChatGPT. Closing that gap typically requires building the kind of long-form, citation-worthy content that earns references from high-authority sources.
What’s the fastest way to cut token costs without changing what I track?
Enable batch processing for any monitoring that doesn’t need to happen in real time. Switch output format from open-ended text to structured minimal fields — brand name, position, sentiment flag. Those two changes typically reduce monthly spend by 50% to 70% with no change to what you’re measuring.
Does traditional SEO (backlinks, domain authority) still influence AI brand visibility?
Less than it used to. AI models weight entity association and information gain more heavily than raw link equity. Pages with original statistics, expert citations, and clear topical authority are cited roughly 30% to 40% more often than pages that rely primarily on inbound links. The optimization target has shifted from link acquisition to content credibility.
At what scale does a purpose-built platform outperform a DIY script?
The crossover typically happens around 50 to 100 prompts tracked per month across two or more platforms. Below that, a well-optimized script can be cost-effective. Above it, the infrastructure overhead — maintenance, compliance, versioning — starts to exceed the cost of a platform subscription.

