
You ran a GEO score checker on your site. The number came back lower than expected, maybe a 32 or a 38, and now you’re trying to figure out what it actually means.
Here’s the thing: a low GEO score isn’t a verdict on your content. It’s a diagnostic. It tells you that somewhere between how you write, what you cite, and how you structure information, there’s friction that’s stopping AI engines from extracting and quoting your pages.
The research is clear on this. According to analysis of over 12,500 queries, 83% of citations in AI Overviews now come from pages outside the traditional organic top 10. Legacy domain authority matters less than it used to. Structure and extractability matter more. That’s what your GEO score is actually measuring.
This guide breaks down the three failure modes by score range, with specific fixes for each one, and shows you how to verify that your changes are actually working.
A Low GEO Score Means AI Can’t Use Your Content
Before diving into fixes, it helps to understand the mechanism.
Generative engines like ChatGPT, Perplexity, and Google AI Overviews don’t read your articles the way a human does. They scan for “citable units”: passages they can extract, attribute, and drop into a synthesized answer. If your content doesn’t yield clean snippets, it gets skipped, regardless of how good the ideas are.
A score below 40 typically reflects one of three problems: the writing is too complex to parse, the source isn’t trusted enough to cite, or the content can’t be extracted in pieces. These aren’t vague quality issues. They’re mechanical failures with specific fixes.
The score range tells you which failure you’re dealing with.
Score 0-25: Your Writing Is Working Against You
At this level, the core problem is linguistic. AI retrieval systems struggle to summarize content when sentences are long, passive voice is overused, or a single paragraph covers multiple ideas without a clear anchor.
Research by Princeton and IIT Delhi found that simplifying language boosts citation rates by 15-30% because it reduces the cognitive load on the LLM’s summarization layer. The data behind this is specific: sentence length under 20 words correlates with citation success at r=0.68, while pronoun ambiguity (using “it” or “they” without a clear antecedent) correlates at r=-0.71, one of the strongest negative signals in the dataset.
The fix: Audit your top five traffic pages and apply three rules. First, one idea per paragraph, with the core claim in the opening sentence. Second, cut sentences to under 20 words where possible. Third, replace vague language with numbers. “Much faster” becomes “reduces load time by 40%.” “Many companies” becomes “over 60% of B2B teams.” Content that can’t maintain at least one verifiable fact per 200 words is frequently filtered out during the reranking phase of the RAG pipeline.

That last point is worth repeating.
A paragraph full of assertions AI can’t verify isn’t just weak, it’s often invisible.
Score 25-40: AI Doesn’t Trust Your Sources
Content in this range is usually well-written. The problem is different: the engine can read it, but it doesn’t feel confident citing it.
Generative engines are under constant pressure to avoid hallucinations. One way they manage this is by prioritizing sources that cite other credible sources. If your content makes claims without pointing to academic papers, industry reports, or named expert opinions, the engine treats those claims as unverified and moves on.
The lift from fixing this is significant. Adding authoritative citations to otherwise well-optimized pages yields up to a 115% improvement in citation probability. Peer-reviewed research carries the highest trust signal, followed by industry benchmarks from firms like Gartner or McKinsey, then named expert quotes. Generic phrases like “studies show” without attribution actually reduce citation probability by 15%.
There’s a recency factor here too. Around 50% of content cited in AI answers is less than 13 weeks old. Stale statistics, even accurate ones, get deprioritized as engines favor fresher takes on the same topic.
The fix: Go through your content and find every claim that isn’t anchored to a named source. Replace “research shows” with a specific citation. Link out to .gov, .edu, or established industry reports. Add one direct quote from an internal subject matter expert or named industry figure per article. Also run an entity audit: check that your brand is described consistently across LinkedIn, G2, Crunchbase, and Wikipedia. Contradictory information across these platforms creates “entity ambiguity” that quietly drags down your trust score.
Score 40-60: Your Content Can’t Be Extracted in Pieces
This range is the most frustrating because you’re close. The writing is clear, the sources are credible, but the content still isn’t getting cited at the rate it should.
The issue is structure. A passage that makes sense in context but falls apart when read in isolation won’t be extracted. AI engines pull chunks, not articles. Each H2 and H3 section needs to be able to stand alone as an answer.
The format you use matters a lot here. Data tables lead to 4.1 times more citations than standard narrative prose. FAQ format achieves a 65% citation probability compared to 18% for regular paragraphs. The heading hierarchy also matters: 68.7% of pages cited in ChatGPT responses follow a strict H1→H2→H3 structure. Vague headings like “More Information” or “Other Considerations” prevent the retrieval system from matching sections to queries.
The fix: Start each H2 section with a direct, self-contained answer sentence. Think of it as an “answer capsule”: a sentence that fully satisfies a specific question even if it’s read without any surrounding context. For example, instead of opening with “When it comes to content structure, there are several things to consider,” write “Content structured with one claim per paragraph and a direct opening sentence is extracted by AI engines at significantly higher rates.” Add FAQ blocks at the end of key articles with explicit question-and-answer formatting. Convert any in-paragraph comparisons to tables.
Fix These in the Right Order
Most teams try to fix everything at once. That makes it impossible to know which change actually moved the needle.
The more effective approach is sequential. Start with writing and structure changes, those are internal edits that can go live within days and have no dependencies. Authority signals take longer because they require outbound citations to be indexed and inbound links to propagate. Running both in parallel just creates noise.
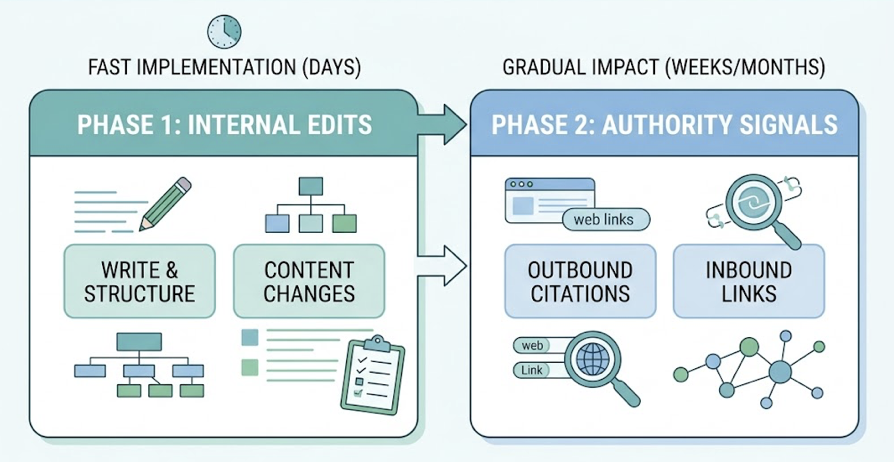
A two-week sprint works well here. In week one, focus on the top five pages by traffic: rewrite sentence structure, add answer capsules to each H2, implement FAQ and Article schema markup. In week two, audit your content for unsupported claims and replace them with specific data points, add at least two external citations per article, and clean up your entity profiles across third-party platforms.
This sequence mirrors what the underlying GEO scoring formula rewards. Across 16 optimization pillars, the strongest individual correlations with citation belong to metadata freshness (r=0.68), semantic HTML (r=0.65), and structured data (r=0.63). The quick wins in week one address all three.
After You Fix It, You Need to Verify It
Here’s the gap most teams run into: they make the changes, and then they have no idea whether it worked.
Traditional analytics tools like Google Search Console don’t track AI citations. They can’t tell you whether ChatGPT started mentioning your brand more often, whether Perplexity is pulling from your updated pages, or whether your authority signals are being recognized by AI indexes. You’re essentially optimizing blind.
The practical starting point is running your URLs through a GEO score checker before and after each round of edits. This gives you a baseline and a delta. A score improvement from 33 to 51 in two weeks tells you the structural changes are working. A score that stays flat tells you to look elsewhere.
For ongoing visibility beyond the score itself, Topify tracks how your brand actually appears inside AI responses across ChatGPT, Gemini, and Perplexity. It monitors mention frequency, sentiment, and position within synthesized answers, the signals that tell you whether optimization is translating to real-world AI visibility. The Source Analysis feature goes one level deeper, showing you exactly which domains AI engines are citing in your category, so you can spot gaps and target the right external placements.
The GEO score is the diagnostic. Continuous monitoring is how you close the loop.
Conclusion
A low GEO score is specific. It points to one of three problems: writing that AI can’t parse, sources AI doesn’t trust, or structure AI can’t extract. Each has a defined fix, and the fixes have a logical order. Start with clarity, then credibility, then structure.
The harder part is knowing whether it’s working. Use a GEO score checker to track before-and-after deltas, and use continuous monitoring to verify that your changes are showing up inside actual AI responses. The brands that close that feedback loop are the ones building durable visibility in the AI search era.
FAQ
What is a good GEO score?
Scores of 61-85 indicate solid optimization with reliable authority signals. Scores above 86 are considered excellent and consistently generate AI citations across multiple platforms. Scores below 60, particularly below 40, point to structural or credibility issues that need to be addressed before expecting consistent citation.
How long does it take to improve a GEO score?
Writing and formatting changes can produce new citation appearances within weeks as crawlers update. Building topical authority through external citations and backlinks typically takes three to six months to compound. The two-week sprint framework covers the fast-moving fixes first.
Does a high GEO score affect ranking in ChatGPT?
Yes, but differently from SEO. A higher GEO score increases the likelihood that ChatGPT’s browser agent selects your page as a candidate source during synthesis. It doesn’t guarantee placement, but it improves the probability significantly.
Can I improve my GEO score without rewriting all my content?
Adding schema markup, updating metadata for freshness, and strengthening your outbound citation profile can all move the score without a full rewrite. That said, structural changes at the paragraph level tend to produce the largest single improvements.
How often should I check my GEO score?
Monthly for established pages in stable niches. Weekly for competitive industries, since citation patterns shift based on model updates and competitor content changes.

