
Most brands run a GEO score check and stop there.
They see a number, screenshot it, maybe share it in a Slack channel, and then… nothing. No action, no follow-through, no visible change in how often AI systems actually recommend them.
That’s the gap most brands still can’t see. A GEO score isn’t a result. It’s a starting point. And without a structured workflow to act on it, the score is just a data point collecting dust.
This guide walks through the five-step process that turns a GEO score into real AI citations — the kind that show up in ChatGPT, Gemini, and Perplexity responses when your ideal customers are making decisions.
Step 1. Run Your GEO Score Check Before You Touch Anything Else
The single most common mistake in GEO programs is optimizing without a baseline. Teams start producing content, updating schema, and chasing citations — all before they know where they actually stand.
In a stochastic environment like large language models, that’s expensive guesswork.
A GEO score check establishes the baseline your entire optimization strategy depends on. It measures how likely your brand is to be cited and recommended by platforms like ChatGPT, Gemini, and Perplexity — not as a single number, but as a weighted composite across six technical and qualitative dimensions:
AI Bot Access is the binary foundation. If your robots.txt blocks crawlers like GPTBot, OAI-SearchBot, ClaudeBot, or PerplexityBot, you’re invisible to the retrieval-augmented generation (RAG) systems powering real-time AI search. Everything else in your GEO strategy becomes irrelevant.
Structured Data measures your JSON-LD schema implementation. Schema acts as a machine-readable identity card — it helps AI engines resolve entities and understand relationships without relying on natural language interpretation.
Visibility tracks how often your brand appears in responses for a set of high-intent industry prompts. This is your Share of Model: the percentage of relevant AI answers where your brand gets a mention.
Sentiment evaluates how AI characterizes your brand when it does mention you. “Leading solution” and “budget alternative” are both citations — but one drives purchase intent and one doesn’t.
Position measures where you appear in the generated answer. A first-position mention carries 32% higher purchase intent than a fourth-position mention, according to generative search research.
Source Coverage tracks the diversity of third-party platforms citing you. AI models are 6.5 times more likely to recommend a brand when multiple independent sources — Reddit, Wikipedia, industry publications — corroborate its authority.
Without this baseline, marketing teams can’t distinguish between a temporary model fluctuation and a systemic failure in their content strategy. The Topify GEO Score Checker runs this diagnostic across all six dimensions and surfaces exactly where the gap is.
Step 2. Your GEO Score Masks More Than It Reveals — Find the Weak Dimension
An aggregate score of 88/100 sounds like “excellent.” It’s often not.
A brand can score well in technical SEO and AI bot access while remaining invisible for every high-intent buying prompt. The overall number smooths over the specific dimension that’s actually dragging performance. That’s where teams waste months optimizing the wrong things.
The diagnostic work in Step 2 is about peeling back the aggregate to find the single weakest dimension. Each dimension has a different failure pattern:
| Dimension | What It Signals | How to Spot It |
|---|---|---|
| Sentiment | AI describes your brand negatively or neutrally | High visibility, low conversion; AI frames you as “expensive” or “complex” |
| Position | Frequent mentions, but always at the bottom of lists | Citations exist, but competitors are named first every time |
| Source Coverage | AI only pulls from your own domain | Zero citations from Reddit, news media, or third-party review sites |
| CVR | Present for informational queries, absent for decision-stage prompts | Mentioned in “what is X” answers, not in “best X for Y” answers |
The recommendation here is counterintuitive: don’t try to fix everything at once. In an LLM environment, shifting too many variables simultaneously makes it impossible to attribute improvements to specific actions. Pick the single most underperforming dimension and run a targeted remediation before touching anything else.
Step 3. Don’t Optimize Blindly — Build a Prompt-Specific Action Plan
GEO optimization is not about producing more content.
It’s about producing content that satisfies the specific retrieval requirements of the engines. Once you’ve identified your weak dimension from Step 2, the response needs to be targeted — not generic.
Different weaknesses require fundamentally different fixes:
Source Coverage deficit: If AI engines only cite your own domain, you have a third-party validation problem. AI systems use something functionally similar to consensus scoring. The fix is earned media and digital PR — securing mentions on Reddit, industry publications, and third-party listicles. Off-site signals are often more effective than any on-page change.
Sentiment deficit: If you’re described as “known for complex setup” or “better for enterprise,” the action plan involves publishing content that directly counters that narrative with evidence. Case studies with specific metrics. Review platform signals from G2 or Trustpilot. AI models synthesize these sources when forming their characterizations.
Position deficit: Research shows that 44.2% of AI citations come from the first 30% of a page’s content. To move from trailing mention to top recommendation, content must lead with a 40-60 word direct answer to the prompt — not a long intro that buries the key information.
The execution gap is where most teams stall. Identifying the fix is one thing. Deploying it across multiple content properties, updating schema, coordinating between writers and developers — that’s where timelines slip by weeks.
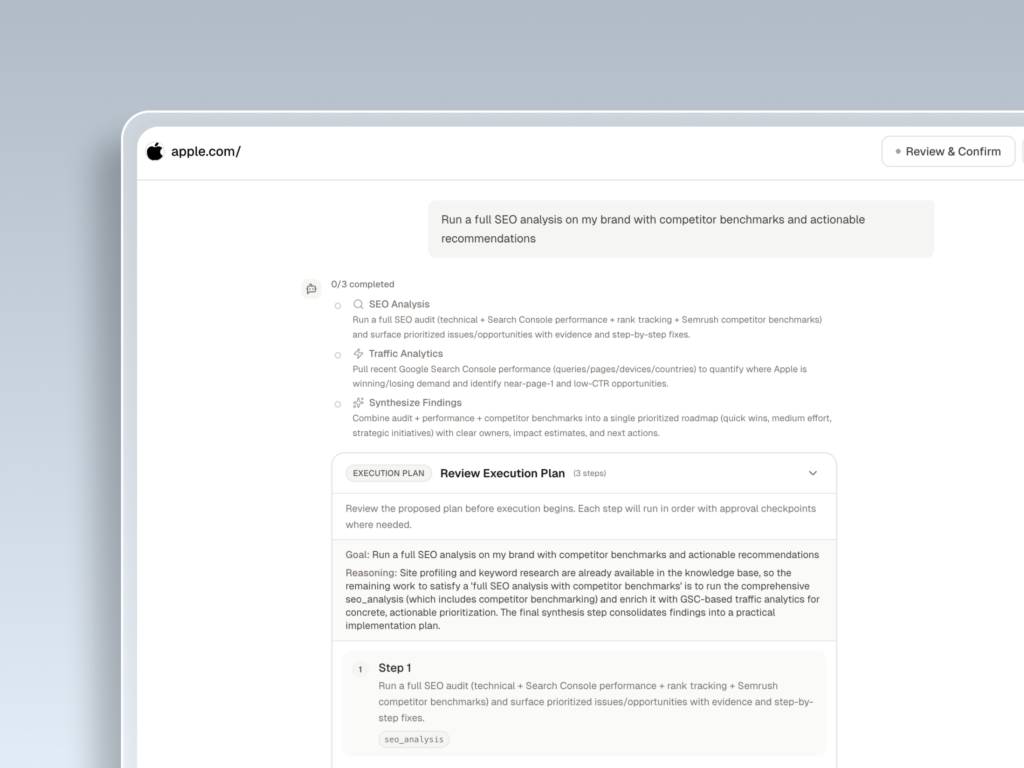
Topify’s One-Click Agent addresses this directly. Define your goal in plain language, review the proposed strategy, and deploy with a single click. The agent handles monitoring, gap detection, content formulation, and direct publishing to your CMS — without requiring manual coordination across teams.
Step 4. Track AI Citations — Not Just Rankings
Here’s what traditional SEO metrics miss entirely: a page can rank #1 on Google and never get cited by ChatGPT.
Ranking and citation are different signals. Generative engines don’t pull from the top of a search index — they pull from content that satisfies the structural requirements of retrieval-augmented generation. A page that ranks well but lacks factual depth, structured data, or third-party corroboration is invisible in AI answers.
That’s why AI citation frequency is the North Star metric for the modern search marketer — not rankings, not impressions.
Citations are the mechanism that preserves the revenue pathway in a zero-click world. While a mention builds awareness, a clickable citation is what drives high-converting referral traffic. Research shows that content incorporating authoritative citations, direct quotes, and relevant statistics achieves 30-40% higher visibility in generative engine responses.
Different platforms also have different citation behaviors:
| Platform | Citation Pattern | What to Prioritize |
|---|---|---|
| ChatGPT | 3-5 sources; favors high-authority editorial sites | Encyclopedic, factual depth |
| Perplexity | 5-12 sources; heavy focus on recency and original data | Monthly updates and data-dense reports |
| Google AIO | Favors answer-first snippets from top rankings | Technical SEO foundation + direct answers |
| Gemini | Trusts institutional sources (.gov, .edu) over UGC | Expert authorship and credentials |
Tracking these citation patterns manually across four platforms is not realistic for any marketing team. Topify’s AI Visibility Tracker queries actual AI platforms and reads real-time responses to determine your Share of Voice. It identifies the specific trigger keywords that cause an AI to mention your brand — and detects the visibility gaps where you should be present but currently aren’t.
That’s the data that informs every decision in the next step.
Step 5. Iteration Is the Product — Set a 30-Day Feedback Cadence
AI search is not a set-and-forget environment. LLMs update constantly. Search indices are dynamic. Content cited yesterday may be ignored by next week.
Freshness is a primary citation signal. Pages updated within the last 14 days are cited 2.3 times more frequently than pages untouched for 60 or more days. After 90 days without updates, citation rates typically plateau at 40% of their initial peak.
| Update Cadence | Citation Probability |
|---|---|
| Continuous (Monthly) | 100% baseline maintained |
| One-Time Optimization | -60% decay within 3 months |
| Biannual Refresh | Significant visibility gaps |
The implication is clear: GEO is an ongoing system, not a campaign. The brands winning AI citations aren’t the ones who ran the best one-time optimization. They’re the ones who built a repeatable monthly cadence.
A 30-day feedback loop looks like this: re-run your GEO score on Day 1 to capture any shifts. Spend Days 2-5 analyzing new weak dimensions or emerging competitor threats. Use Days 6-10 to execute — update content, add statistics, refresh expert quotes. Then monitor recovery metrics through the rest of the cycle and prepare for the next iteration.
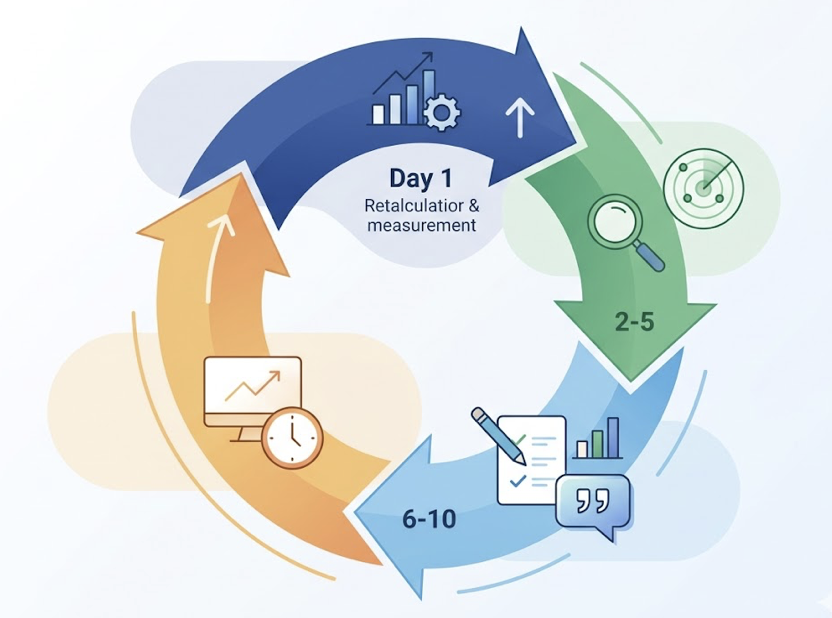
Topify’s AI Agent automates the execution layer of this loop. It continuously monitors your brand’s presence, identifies when citation rates drop, and proactively deploys fixes without requiring a manual trigger. You define the goals; the system handles the cadence.
Why Most Teams Get Stuck After Step 1
The gap between brands winning at GEO and those falling behind isn’t usually a matter of effort. It’s a matter of integration.
Most marketing teams run three separate workflows: a tracking tool, a strategy planning process, and a content execution platform. These rarely talk to each other. When AI citation rates drop, the delay between identifying the problem and deploying a fix can stretch to weeks — and in an environment with a strong recency bias, that delay is expensive.
That’s the structural problem Topify was built to solve.
| Approach | Result | Key Weakness |
|---|---|---|
| Score Only | Temporary awareness of decline | No mechanism for fast recovery; manual work blocks progress |
| Fragmented Execution | Inconsistent visibility across engines | High coordination costs; updates lag citation decay |
| Topify Closed-Loop | Sustained citation leadership | Requires commitment to an automated, iterative workflow |
Topify is the only platform that unifies AI search tracking, GEO optimization strategy, and content execution in a single system. From running your first GEO score check to publishing optimized content and monitoring real-time citation changes, the entire workflow runs in one place — without coordination overhead.
That closed-loop structure is what separates brands that maintain AI visibility from those who constantly play catch-up.
Conclusion
A GEO score tells you where you stand. It doesn’t tell you what to do next — and that’s the gap most brands don’t close.
The five-step workflow here — baseline check, weak dimension diagnosis, targeted action plan, citation tracking, and continuous iteration — is what turns a number into a system. Each step feeds the next. And each cycle of the loop compounds on the one before it.
In a world where 90% of B2B buyers use AI tools at some point in their purchasing journey, and AI-referred visitors convert at up to 4.4 times the rate of traditional organic visitors, the brands that build this system now are establishing a durable advantage. The ones that don’t will keep wondering why their score looks fine but no one’s citing them.
FAQ
What is a GEO score and how is it calculated?
A GEO score measures a website’s readiness for AI search engines. It’s calculated using a weighted methodology across six dimensions: AI Citability (25%), Brand Authority (20%), Content E-E-A-T (20%), Technical SEO (15%), Schema Markup (10%), and Platform Readiness (10%).
How often should I check my GEO score?
Weekly for high-competition industries; monthly at a minimum for others. Citation frequency drops significantly after 30 days without updates, so a monthly check is the baseline for maintaining visibility.
What is a good GEO score?
A score of 70 or above is considered good. Scores of 85 or above indicate that AI engines likely treat your brand as a primary source of authority for relevant prompts.
Can I improve my AI citations without changing my website?
Yes. Off-site signals carry significant weight. Increasing your Source Coverage by securing mentions on Reddit, Wikipedia, and authoritative third-party media is often more effective than on-page changes alone.
How long does it take to see results after GEO optimization?
Changes targeting real-time engines like Perplexity can appear within hours or days. For indexed engines like ChatGPT or Google AI Overviews, meaningful improvement typically takes 3 to 8 weeks.

