
G2 ranks AEO tools by satisfaction and market presence. Neither score tells you whether the tool can handle what LLMs actually do.
You opened G2. You filtered by “Answer Engine Optimization.” You sorted by highest rated.
That’s a reasonable starting point. But here’s the thing: the two dimensions G2 uses to rank software — user satisfaction and market presence — were designed to evaluate CRMs and project management tools. They measure how easy the UI is, how responsive the support team is, and how big the company is. None of that tells you whether a tool can handle the one thing that makes AEO fundamentally different from every other software category: LLM non-determinism.

Run the same query twice, 30 seconds apart. You may get different brand citations, different positions, different sentiment. Tools that rely on API caches or static snapshots will systematically undercount this variance. And they’ll do it in a way that looks fine on a dashboard.
That’s the gap G2 scores can’t show you.
Here’s a five-part framework that does.
Why G2 Scores Are a Starting Point, Not a Verdict
G2’s Satisfaction score is built on review breadth, recency, and net promoter ratings. Its Market Presence score factors in employee count, revenue, and social footprint. Both are legitimate signals for evaluating a project management tool or a CRM.
For AEO tools, they miss the point.
A tool with a polished UI and 24/7 live chat support can score in the top 10% on G2 while its underlying crawler fails to bypass LLM rate limits. A legacy SEO platform with 10,000 employees can dominate the Leaders quadrant after bolting a thin AI monitoring layer onto a five-year-old architecture.
High satisfaction doesn’t mean accurate data.
G2’s review cycle also updates quarterly. AI model weights can shift after any single API call. That speed gap — human review cadence vs. model inference updates — means G2 scores are always looking backward in a category that punishes lag.
Use G2 to build your shortlist. Then run it through the five checks below.
Check #1 — Does It Re-Run Queries Live, or Pull From a Cache?
This is the most important question you can ask any AEO vendor.
LLMs are non-deterministic by design. Even when Temperature is set to 0 — theoretically a deterministic greedy decoding mode — production API calls still produce variable outputs. The reasons are technical: floating-point rounding differences across parallel GPU threads, Mixture-of-Experts routing logic that shifts under continuous batching, and dynamic inference optimizations like prefix caching that change execution context from one call to the next.
The practical consequence: accuracy rates for the same prompt can vary by up to 15% across runs. In extreme cases, the gap between best and worst performance reaches 70%.
A tool that runs one query and caches the result for a week is showing you a single probability event, not your brand’s actual visibility distribution.
Professional-grade platforms handle this with live re-runs: multiple independent queries across time windows and batching environments for the same prompt. The output isn’t a binary “mentioned / not mentioned.” It’s a probability distribution. That’s Visibility Tracking done correctly.
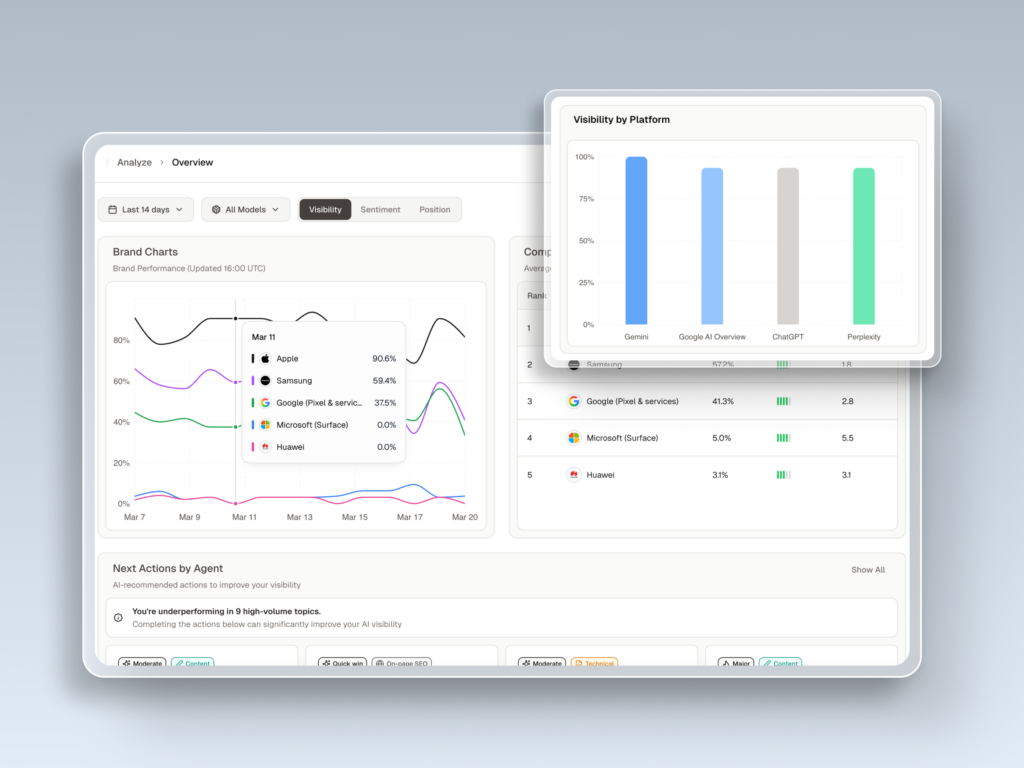
When you’re in a vendor demo, ask one question: “For a single prompt, how many independent queries do you run? How do you model variance across runs?” If the answer is vague, the data quality probably is too.
Check #2 — How Many AI Platforms Does It Actually Cover?
Most tools that score well on G2 were built when “AI search” meant Google AI Overviews. That’s an understandable origin, but the market has fragmented significantly since then.
As of early 2026, ChatGPT holds somewhere between 60% and 77% of AI-driven search and discovery traffic. Google Gemini sits at roughly 15%, Microsoft Copilot at 12.5%, and Perplexity at 5.4%. Claude AI is at 5.0% but growing faster than most — up 14% quarter over quarter.
A tool that only monitors Google AIO leaves you blind to the conversations happening in ChatGPT. That’s three out of four AI interactions you’re not seeing.
Each platform also retrieves and cites information differently. Perplexity operates more like an AI-native search engine, relying on real-time web crawling and explicit inline citations — which is why tracking tools like Brandmentions have built dedicated Perplexity monitoring features. Google AIO correlates closely with traditional organic ranking signals. ChatGPT draws on training data, RAG retrieval, and browsing — a completely different influence model.
You can’t optimize across platforms you can’t see.
Topify tracks across 7+ AI platforms including ChatGPT, Gemini, Perplexity, Claude, DeepSeek, Grok, and others. For a brand with any international or multi-channel presence, that coverage isn’t a nice-to-have. It’s risk mitigation.
Check #3 — Can It Measure Position, Not Just Presence?
“Your brand appeared in 50% of AI answers this month.”
That sounds positive. But if your brand appeared last in a five-item list every single time, that number is misleading you.
Research into Answer Placement Scores (APS) shows that the first recommendation in an AI-generated list carries a weight of 1.0. The second position drops to roughly 0.6. By the third position and beyond, weight falls below 0.3 — which in a conversational context is functionally invisible. AI answers don’t come with a “see all results” button.
Mention count without position is noise dressed up as data.
There’s a second layer that matters equally: sentiment. AI doesn’t just list brands — it characterizes them. Being described as “a budget-friendly option with limited enterprise features” and being described as “the most reliable choice for compliance-heavy teams” are both citations. They produce opposite outcomes for your pipeline.
Advanced platforms combine position tracking with sentiment polarity analysis, identifying not just where your brand appears but how it’s described — and whether those descriptions align with your positioning. Topify’s Competitor Monitoring surfaces both: where you rank relative to competitors on specific prompts, and when AI characterizations shift in tone.
That’s the difference between brand monitoring and brand intelligence.
Check #4 — Does the Data Update Daily, or Weekly?
Google AI Overview trigger rates jumped from 25% to over 60% in 2025. For informational and educational queries, that shift drove a 61% decline in traditional organic click-through rates. The landscape isn’t just changing — it’s changing faster than most marketing teams can track.
Three forces drive AI recommendation volatility: model provider weight updates (like OpenAI system prompt changes), real-time RAG retrieval pulling in newly published competitor content, and the compounding effect of third-party citation signals accumulating over time.
A weekly report can’t catch any of that in time to act.
Weekly-cadence tools are post-mortems. By the time the report lands, the ranking shift that pushed your brand out of the top position happened four days ago. A competitor published new structured content, AI picked it up within hours, and you’re already behind.
Daily monitoring with meaningful analysis volume is what makes AEO actionable. Topify’s Basic plan supports up to 9,000 AI answer analyses per month — enough to run core prompts multiple times daily and build a visibility curve instead of a weekly snapshot. That curve is what lets a team catch a ranking drop within 24 hours of the triggering event, not after the next report cycle.
Speed of insight is a structural advantage. Tools that can’t offer it cost you more than their subscription price.
Check #5 — Does It Tell You What to Do Next?
Most G2-ranked AEO tools are reporting tools. They surface data. Then they hand you a dashboard and leave the execution entirely to your team.
Here’s what that actually looks like in practice: your team sees a visibility gap, manually re-analyzes keyword intent, rewrites content in an answer-first structure, updates the CMS, and then needs to build third-party citations on Reddit, LinkedIn, and Quora to generate the signal AI models actually prioritize. Each of those steps introduces lag. Each step is where strategies stall.
Data without execution is just a more expensive form of anxiety.
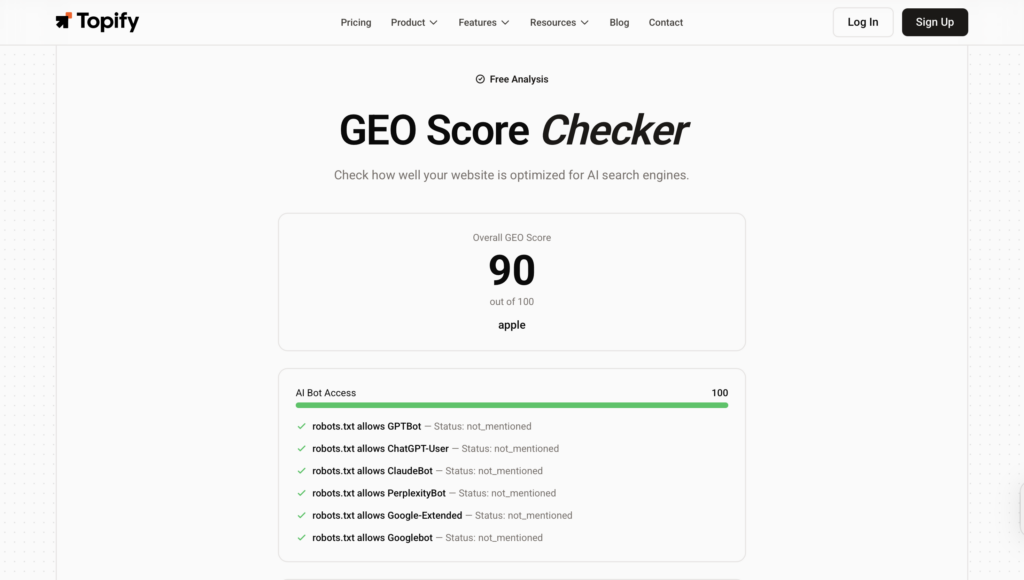
The next category of AEO platforms closes that loop. Topify’s GEO Score Checker evaluates existing pages against specific AI platform retrieval preferences in real time. Its One-Click Execution takes those insights and deploys optimized content — structured answers, schema markup, entity signals — directly through CMS integrations, without a manual rebuild workflow.
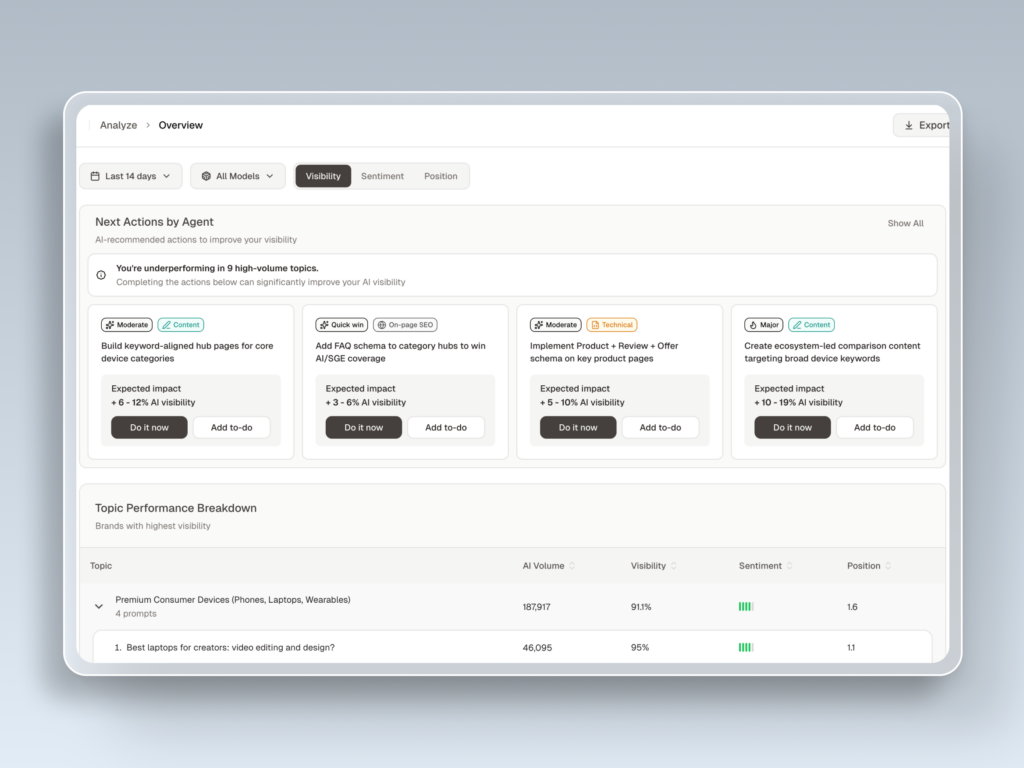
Most tools stop at data. That’s where the real work begins.
That gap between reporting and executing is the clearest product-generation difference in the AEO market right now. It’s also the one you’ll never spot on a G2 listing page.
How to Use This Framework on G2 Right Now
G2 is still a useful discovery funnel. The problem isn’t where you start — it’s where you stop.
When you’re on a vendor’s G2 listing page, look past the star rating and check for these signals: does the feature list mention “LLM tracking,” “entity extraction,” or “generative AI optimization” specifically — not just generic “SEO”? Do their customer case studies reference AEO-specific KPIs like Citation Share or Answer Placement Score, or are they still talking about keyword rankings and backlinks? Search the review text for words like “accuracy,” “real-time,” and “caching” — user frustration about data lag often shows up there before it shows up in the aggregate score.
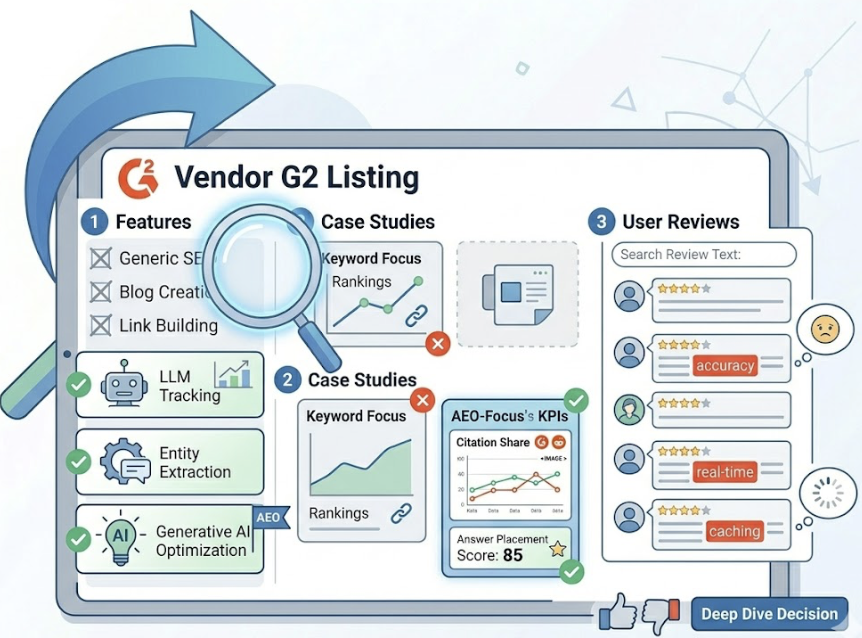
In a demo or trial, three questions will tell you everything:
Ask how they handle LLM non-determinism: do they run multiple queries per prompt, and what’s their variance modeling methodology? Ask whether they can distinguish between a positive brand mention with no link and a negative mention with a link in terms of sentiment scoring. Ask whether they have a direct path from insight to content deployment — not just a report, but an execution workflow.
Here’s how the five dimensions stack up across tool types:
| Evaluation Dimension | Topify | Typical G2 High-Scorer |
|---|---|---|
| Data Collection | Live multi-run queries, variance modeled | API cache or static snapshot |
| Platform Coverage | 7+ platforms including DeepSeek, Grok | Usually Google AIO or one other |
| Measurement Depth | APS position + sentiment + entity association | Basic mention count |
| Update Frequency | Daily monitoring, 9,000+ analyses/mo | Weekly or monthly reports |
| Execution Capability | GEO Score + one-click CMS deployment | Report only, manual follow-through |
Conclusion
G2 is where you discover tools. It’s not where you evaluate them.
AEO is a category where the underlying technology runs on probabilistic systems that change faster than human review cycles can track. The tools that look good on a satisfaction survey may be the same ones feeding you cached snapshots from a week ago and calling it a visibility score.
The five checks above aren’t exhaustive. But they force the right conversations — about data collection methodology, platform coverage, position granularity, update cadence, and execution capability. Those are the questions that separate a dashboard from a platform that actually moves your brand in AI answers.
See it work, then test it on your own brand. Explore how Topify handles these exact dimensions on the platform, or run your own brand through the GEO Score Checker for free before committing to anything.
FAQ
Q1: What does AEO mean on G2?
On G2, AEO (Answer Engine Optimization) typically sits within the SEO or AI marketing software categories. It refers to tools that help brands get cited directly by AI assistants like ChatGPT and Gemini, and AI search engines like Perplexity and Google AI Overviews, rather than just ranking in traditional blue-link results.
Q2: How is AEO different from traditional SEO tools?
Traditional SEO optimizes for clicks on indexed links. AEO optimizes for citations and mentions in AI-generated answers. The signals that matter are different: entity authority, structured content readability, answer-first formatting, and third-party citation signals — not just keyword density or backlink count.
Q3: What’s the most important feature to check in an AEO tool?
Data collection robustness. If a tool can’t demonstrate how it handles LLM output variance — ideally through live multi-run query execution — then the visibility numbers it produces aren’t reliable. After that, execution capability: a tool that only reports without offering an optimization workflow shifts the labor cost to your team without reducing it.
Q4: Can I trust G2 ratings for AEO tools?
Partially. G2 is a useful discovery layer and reflects genuine user satisfaction around UI and support quality. What it doesn’t capture is algorithmic depth, real-time data accuracy, or the technical ability to handle non-deterministic AI outputs. Most reviewers on G2 are evaluating AEO tools through a traditional SEO lens, which means the ratings reflect a different set of priorities than what the category actually requires.

