
You ask ChatGPT to recommend a project management tool. It lists five names. Yours isn’t one of them.
That’s not a coincidence. It’s a competitive gap you can measure, analyze, and close. But only if you know what to look for.
AI search competitor analysis works differently from anything in traditional SEO. There are no keyword rankings to check, no SERP positions to screenshot. Instead, you’re tracking citation frequency, brand mention rates, and share of voice inside synthesized answers generated in real time. The brands that understand this are already pulling ahead.
Most Brands Don’t Know They’re Losing AI Search Share Until It’s Too Late
Traditional search volume is projected to decline 25% by 2026, and most of that volume isn’t going nowhere. It’s going to AI.
ChatGPT alone now handles over 1 billion queries per day with 800 million weekly active users. When AI Overviews are present in a search result, zero-click rates hit 83%. For Google’s AI Mode, that number reaches 93%. If your brand isn’t being cited inside the answer, you’re not just ranking lower. You effectively don’t exist for that user.
That’s the gap most brands still can’t see.
Meanwhile, your competitors aren’t invisible. They’re being recommended by name, described favorably, and positioned as trusted choices. They didn’t get there by luck. Their content, their citation profile, and their prompt-level coverage created a pattern that AI models have learned to trust. AI search competitor analysis is how you reverse-engineer that pattern.
The 4 Metrics That Reveal Your Competitor’s AI Visibility
Competitive AI visibility isn’t a single number. It’s a combination of four dimensions that together tell you where a competitor is winning and why.
Visibility Rate (sometimes called Answer Inclusion Rate) measures how often a competitor appears across a defined set of category-relevant prompts. If a rival shows up in 80% of “best tool for remote teams” queries while you show up in 10%, they’ve built structural authority in that topic space. You haven’t.
Share of Voice in AI search calculates your competitor’s mentions as a percentage of all brand mentions in a category. AI engines typically limit recommendations to 3–5 brands per answer, which means share of voice in this context is genuinely zero-sum. When a competitor gains, you lose a slot.
Recommended Position determines where in the response a brand appears. Research shows brands mentioned in the first two sentences of an AI response receive 5x more consideration than those mentioned later. Being included isn’t enough. Where you’re included changes everything.
Sentiment tracks how the AI describes a competitor. High visibility with neutral or negative framing is a warning sign for them and an opportunity for you. An AI that describes a competitor as “a budget option with limited support” is damaging their brand equity with every recommendation.
Across these four dimensions, a full picture of competitor AI visibility starts to emerge. The next question is: what’s driving it at the prompt level?
How to Discover Which Prompts Trigger Competitor Brand Mentions
When a competitor is recommended and you’re not, something specific happened at the prompt level. Understanding that mechanism is the core of AI search competitive intelligence.
AI systems don’t evaluate websites. They process language patterns. When a user asks a question, most major AI platforms decompose it into 8–12 parallel sub-queries to retrieve information from across the web. Many of these sub-queries carry zero traditional search volume. They’re invisible to Google Search Console. But they’re actively driving AI recommendations.
This is where competitors often build their edge quietly. A user asks: “Which CRM works best for a five-person non-profit?” The AI fans out to sub-queries about non-profit pricing tiers, ease of use for small teams, and donor software integrations. A competitor who’s built content that answers those specific intent layers gets retrieved and cited. Even if they’ve never ranked for the original broad keyword.
The methodology for prompt-level competitor analysis follows a clear structure: identify a broad corpus of relevant questions, categorize them by buyer journey stage, run them across multiple AI platforms, and look for where competitors appear while you don’t. That gap list is your content priority queue.
Topify‘s High-Value Prompt Discovery automates this process, tracking between 100 and 250 prompts per plan across ChatGPT, Gemini, Perplexity, and other platforms. Instead of manually probing queries one by one, you get a real-time map of which specific triggers are favoring competitors. That turns a research task that would take weeks into a structured, repeatable workflow.
Consider what this looks like in practice. A SaaS brand discovers a competitor is cited every time someone asks about “Agile workflows for distributed teams.” The source isn’t their homepage. It’s a comprehensive Agile Frameworks Guide the AI consistently uses as a grounding reference. An e-commerce brand finds a rival is recommended for “eco-friendly sneakers under $100” because their product pages include structured data with clear price and material definitions the AI can extract cleanly. A marketing agency notices a competitor is cited for “B2B lead generation trends 2026” because a LinkedIn thought-leadership post got picked up by the AI’s real-time retrieval system.
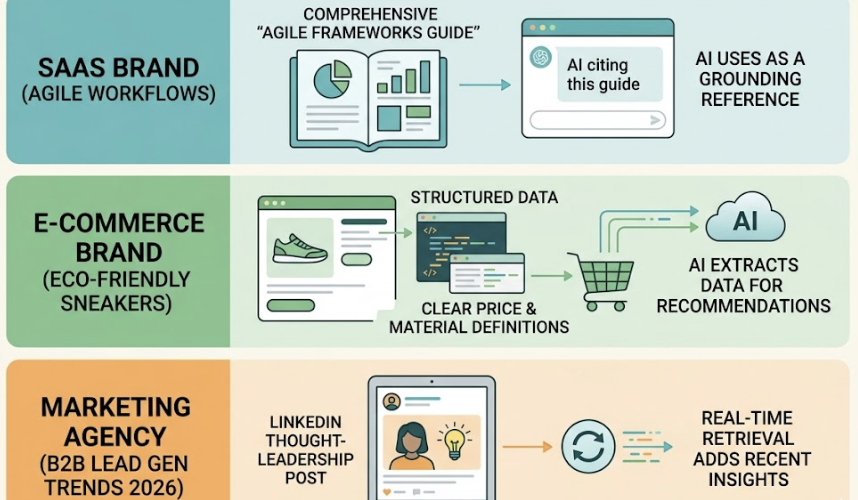
None of these are accidents. They’re patterns you can identify and replicate.
Reverse-Engineering Competitor Citation Sources in AI Platforms
Knowing that a competitor is visible isn’t enough. You need to know where that visibility is coming from.
In traditional SEO, authority flows through backlinks. In AI search, authority flows through citations. And they’re not the same thing. Research shows brand mentions across the web correlate at r=0.664 with AI visibility, while backlink quality correlates at only r=0.218. The AI isn’t primarily trusting your link profile. It’s trusting the consensus built by third-party sources that mention your brand favorably and consistently.
The citation breakdown for most branded AI recommendations follows a predictable pattern: earned media accounts for roughly 48% of citations, commercial brand content around 30%, owned website content around 23%, and reference sites like Wikipedia or Product Hunt around 10%. Your website, in other words, is the weakest source of AI authority you own.
This reframes the entire question of how competitors build AI visibility. If a rival is being recommended, the most likely reason isn’t that their homepage is better. It’s that industry blogs, niche publications, and forum discussions have built an independent case for them that the AI finds credible. Brands mentioned positively across at least four non-affiliated forums are 2.8x more likely to appear in ChatGPT responses.
Topify’s Source Analysis tracks the exact domains and URLs that AI platforms are citing when they recommend a competitor. This reveals the “source gap” directly. You can see whether the AI is citing academic content, Reddit threads, YouTube reviews, or niche industry directories. Each source type points to a different content strategy. If a competitor’s visibility is anchored in Reddit and Wikipedia, the fix isn’t on-page optimization. It’s digital PR, community engagement, and unlinked brand mention acquisition.
Competitor GEO Benchmarking Across Platforms: Why One Platform Isn’t Enough
Here’s a structural issue that most brands miss when they start tracking competitor AI visibility: leading on one platform doesn’t mean you’re leading anywhere else.
ChatGPT cites Wikipedia at 7.8% and tends toward nuanced, detailed brand comparisons, averaging 5.84 brands per response. Perplexity cites Reddit at 6.6% and favors fact-dense, research-backed sources, averaging 4.37 brands. Google AI Overviews prioritizes YouTube at 62.4% and pulls heavily from the Google ecosystem. These aren’t minor differences in preference. They represent fundamentally different citation architectures, which means a competitor’s visibility can vary dramatically across platforms depending on where they’ve built their content presence.
A complete competitor GEO benchmarking program runs across at least ChatGPT, Gemini, Perplexity, and Google AI Mode simultaneously, using a standardized set of prompts to compare mention rates, share of voice, and position for each rival. The goal is to identify where the competitive gap is widest and which platforms represent the highest opportunity.
Topify’s Dynamic Competitor Benchmarking automates this multi-platform tracking from a single dashboard. It automatically detects new competitors appearing in your category, monitors real-time shifts in visibility, and surfaces emerging rivals before they become established threats. That kind of early detection is what separates a reactive GEO strategy from a proactive one.
Benchmarking also answers a question that’s often overlooked: is your competitor strong across all platforms, or only on one or two? A competitor who dominates in ChatGPT but barely appears in Google AI Overviews has a fragile position. That’s a specific, exploitable gap.
Competitive benchmarking isn’t a one-time project. Model updates, new training data, and shifts in citation patterns mean that a baseline from six months ago may no longer reflect current reality. Weekly audits for high-value commercial prompts and monthly reviews for broader category trends is a reasonable cadence for most teams.
Turning Competitive GEO Analysis Into a Content Strategy That Actually Wins
The analysis is the map. The content strategy is how you move.
After running a competitive AI search analysis, most brands identify three types of gaps, each requiring a different response. Understanding which gap is largest tells you where to start.
The first is a Prompt-Intent Gap: competitors are appearing for high-value buyer prompts where you’re absent entirely. This is the most urgent situation. The fix is creating authoritative “cornerstone” content that covers the intent directly. Answer-first structure (leading every section with a 50–100 word direct summary), comprehensive topic coverage, and structured formatting using H2/H3 hierarchies and Markdown tables all improve the likelihood that AI systems can retrieve and cite your content cleanly.
The second is a Media and Citation Gap: competitors are recommended because they’re cited by third-party domains that don’t mention you. This is an off-page GEO problem. Digital PR, subject-matter expert contributions to industry forums, and consistent community presence on platforms the AI favors are the right responses here. Ranking on Google won’t fix this. Building a mention profile across independent sources will.
The third is a Sentiment and Narrative Gap: you’re appearing in AI responses, but the AI describes you less favorably than competitors. This often happens when a brand’s own content is ambiguous or outdated. AI models fill information gaps with whatever they can find, including outdated reviews, forum complaints, or competitor comparison pages. Auditing and updating your “single source of truth” pages (pricing, features, about) with clear, declarative definitions gives the AI accurate material to work with.
Topify’s One-Click Execution connects this analysis directly to action. You state your goals in plain English, review the proposed content strategy, and deploy it. Instead of insights sitting in a dashboard, they get translated into GEO-ready content and optimized execution. That’s the step where most teams lose momentum, and it’s where automation makes the biggest difference.
Competitive analysis isn’t the destination. It’s the starting point.
Conclusion
The brands winning AI search in 2026 aren’t doing it by accident. They’ve mapped which prompts trigger competitor recommendations, traced the citation sources behind that visibility, benchmarked performance across platforms, and turned those findings into a content roadmap that systematically closes the gap.
None of this requires guessing. It requires measurement. AI search competitor analysis gives you a repeatable framework to understand exactly where competitors are ahead, why they’re ahead, and what it would take to change that. The gap is visible. The path is clear. Starting the analysis is the only step that’s actually in your control.
FAQ
How do I find out which AI platforms recommend my competitors?
Manual probing of ChatGPT, Gemini, and Perplexity with high-intent prompts is a starting point, but it captures only a small slice of the AI recommendation landscape. Systematic tracking requires a GEO platform that can run hundreds of prompts across multiple regions and timeframes to account for the non-deterministic nature of AI responses.
What’s the difference between AI share of voice and traditional search share?
Traditional search share is based on keyword rankings and estimated click-through rates from a results list. AI share of voice measures how often your brand appears inside a synthesized recommendation, relative to all other brands mentioned. Because AI responses increasingly result in zero-click outcomes, share of voice in AI search is closer to a “consideration” metric than a traffic metric.
How often should I run a competitive GEO analysis?
Weekly audits for high-priority commercial prompts and monthly reviews for broader category trends is the standard for most teams. Model updates and the ingestion of new training data can shift citation patterns quickly, so a static quarterly benchmark isn’t enough.
Can competitor backlink profiles influence AI search visibility?
Backlinks still play a supporting role, but their influence is secondary to brand mentions. Backlink quality correlates at r=0.218 with AI visibility, compared to r=0.664 for brand mentions across independent sources. In AI search, backlinks act as reputation signals that help models evaluate source credibility, but they’re not the primary driver of who gets recommended.
What does a healthy competitor monitoring workflow look like?
It starts with selecting 3–5 direct rivals, establishing a visibility baseline across a standardized set of 100 or more prompts, and tracking their citation sources across platforms. Those findings feed into a regular content sprint to address prompt-intent gaps, citation gaps, and sentiment gaps. The key is making the workflow repeatable, not just running it once.

