
Your domain authority is solid. Your keyword rankings held through the last algorithm update. But none of that tells you whether ChatGPT is recommending your competitor every time a prospect asks about your category.
That’s the real gap in most digital strategies right now. Research shows 62% of brands are effectively invisible to generative AI models, and in 81% of tested cases, AI failed to cite recognized market leaders when users asked direct, unbranded category questions. These brands weren’t outranked. They were simply absent. An AI recommendation tracking strategy is how you find out where you stand, and what to do about it.
Why Your Google Rankings Don’t Reflect Your AI Recommendation Tracking Strategy
Traditional SEO and AI recommendation tracking measure fundamentally different things.
Traditional SEO tracks retrieval: which position you hold in a list of results. AI recommendation tracking measures selection: whether a language model synthesizes your brand into its final answer. That’s a structural shift in how visibility works, not a tactical tweak.
65% of searches now end without a single click because the AI delivers the answer directly within the interface. The goal is no longer to appear somewhere in positions one through ten. It’s to be chosen when the model constructs its response.
| Traditional SEO Tracking | AI Recommendation Tracking | |
|---|---|---|
| Core mechanism | Keyword retrieval, link indexing | Probabilistic synthesis, RAG retrieval |
| Success metric | Ranking position, organic clicks | Mention rate, citation frequency |
| User behavior | Short queries on search engines | Complex prompts on AI assistants |
| Result format | List of blue links | Synthesized narrative or recommendation |
| Goal | Get found | Get chosen |
Here’s the thing: a brand’s overall authority correlates three times more strongly with AI citations than with any individual keyword ranking. AI models prioritize entities they recognize across multiple contexts. Broad authority now outperforms narrow keyword optimization.
The 5 Search Visibility Metrics Behind a Working AI Recommendation Tracking Strategy
Most teams track the wrong things. Here are the five numbers that actually reflect how AI recommends your brand.
1. Mention Rate
The percentage of relevant AI prompts where your brand appears. This is your baseline. Category leaders typically see mention rates of 30–50% across core use-case queries. Below 10% in your primary topic cluster means the model doesn’t have sufficient entity recognition of your brand, and users searching that topic will never encounter you.
2. Position in AI Answer
When AI does mention your brand, where does it appear? First mention signals the highest confidence. A target of average position 2.0 or better on high-intent “best of” queries is the benchmark to work toward. In platforms like Perplexity, the first cited source pulls the overwhelming majority of engagement.
3. Sentiment Score
High visibility with negative framing is worse than low visibility. AI models amplify existing web sentiment. If your third-party coverage is mixed, that’s what the model reflects back to users. A score of 70% or higher positive ratio is healthy. Below 60% warrants an immediate audit of review profiles and third-party coverage.
4. Source Citation Rate
When AI cites your domain or specific pages, that’s the primary driver of actual referral traffic. Target a citation-to-mention ratio of at least 30%. Lower than that means your content is being paraphrased without attribution, and you’re capturing zero traffic from those mentions.
5. Prompt Coverage
The percentage of your target prompts that trigger a brand mention. This reveals content gaps faster than any site audit. A coverage of 60% or more across your primary topic cluster is healthy. If you’re only appearing on branded queries, you’re missing most of the discovery happening in AI search right now.
| Metric | What It Measures | Healthy Range | When It’s Below Threshold |
|---|---|---|---|
| Mention Rate | Brand awareness in AI | 30–50% across core queries | Entity recognition gap |
| Position | Recommendation strength | Avg ≤2.0 on high-intent prompts | Authority gap vs. competitors |
| Sentiment | Reputation tone | ≥70% positive ratio | Third-party coverage issue |
| Citation Rate | Traffic potential | ≥30% citation-to-mention | Content trust gap in RAG pipeline |
| Prompt Coverage | Market influence | ≥60% of target prompt set | Content gap in topic cluster |
How to Set Up Your AI Recommendation Tracking Without Starting From Scratch
Step 1: Prioritize your platforms.
ChatGPT, Gemini, and Perplexity are the non-negotiables. ChatGPT accounts for roughly 70–87% of measured AI referral traffic. Perplexity matters for citation-heavy research queries. Google AI Overviews has the broadest reach in general search.
Don’t optimize for one and assume the rest follow. There’s only a 13.7% citation overlap between Google AI Overviews and other AI platforms, even when they reach similar conclusions. Cross-platform tracking isn’t optional. It’s where the real gaps show up.
Step 2: Build your prompt library from real customer language.
Don’t test vanity queries. Build from support tickets, sales call transcripts, and review platforms. A solid library covers three types:
- Branded: “Is [Brand] reliable for [use case]?”
- Category: “What’s the best tool for [specific task]?”
- Problem-solution: “How do I solve [specific problem]?”
Twenty to thirty standardized prompts per core topic gives you statistically stable data week over week. Fewer than that, and trend detection becomes unreliable.
Step 3: Automate the execution.
Manual audits don’t hold up here. AI responses are probabilistic, meaning the same prompt returns different answers across sessions. You need to run hundreds of prompt variations on a consistent cadence to produce a visibility score you can act on.
Topify automates this process across ChatGPT, Gemini, Perplexity, DeepSeek, and other major platforms. It tracks all five core metrics in a unified dashboard, surfaces competitor positioning data in real time, and continuously identifies new high-value prompts as AI recommendation patterns shift. Built by founding researchers from OpenAI and Google SEO practitioners, the platform is designed for teams that need precision, not approximations. The Basic plan starts at $99/month with 100 prompts and 9,000 AI answer analyses per month.
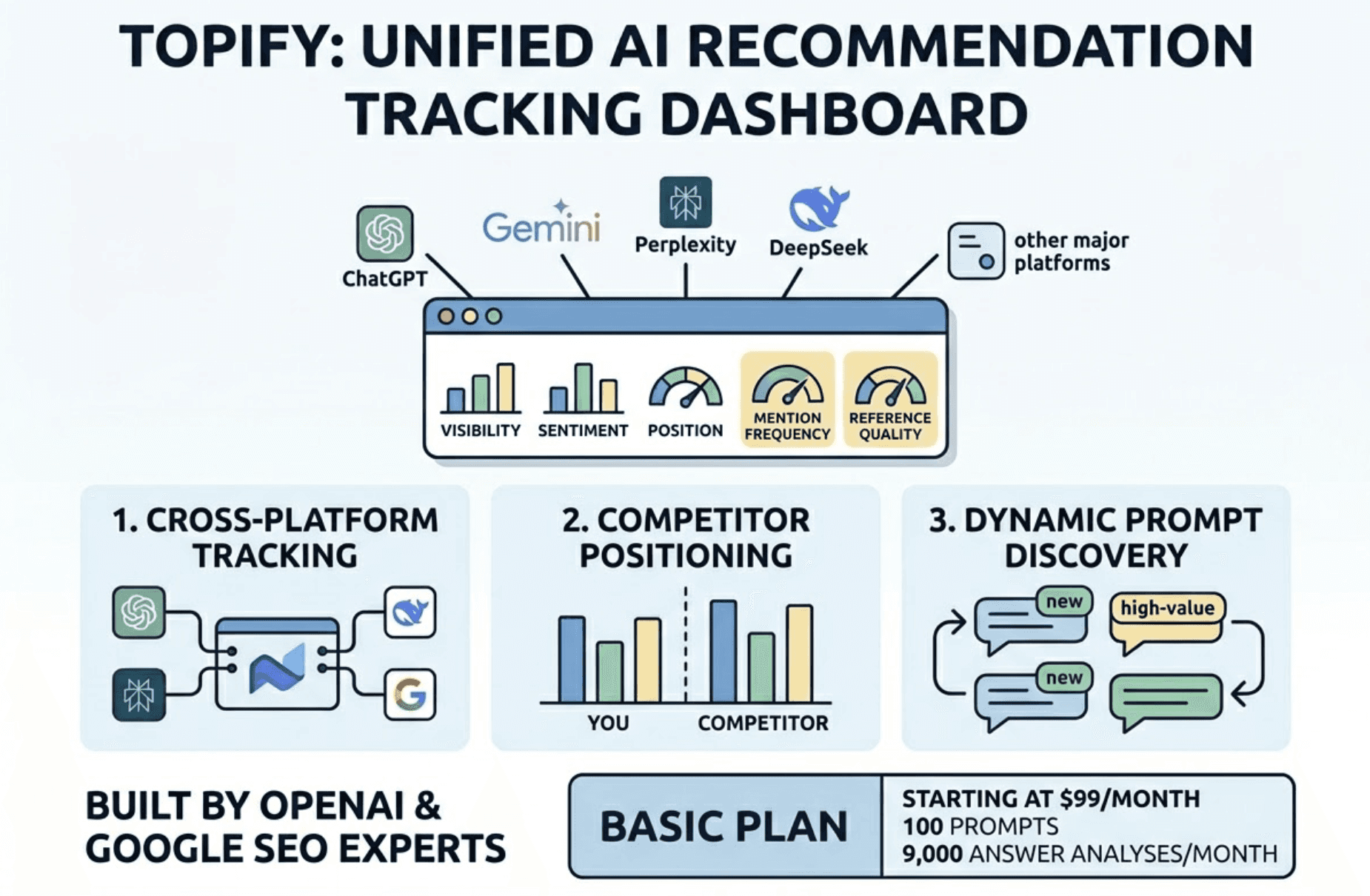
Step 4: Set your tracking cadence.
Weekly is the minimum. Daily for queries tied directly to revenue or competitive positioning. Model updates can shift your visibility overnight.
Monthly audits will miss it entirely.
4 Signs Your AI Tracking Data Is Misleading You
Getting numbers is easy. Getting numbers that mean something is harder. These are the four mistakes that consistently lead teams to invest in the wrong optimizations.
Tracking only branded prompts. Testing queries that include your brand name only measures retention, not discovery. The majority of new AI-driven discovery happens on unbranded category prompts. If your prompt library is mostly “Is [Brand] good for X?”, you’re looking at the wrong data.
Testing too infrequently. LLMs sample responses differently each time, even with identical inputs. A monthly test is statistically unreliable. You need enough volume across enough time to distinguish a real trend from random model variance.
Optimizing for a single platform. Ranking well in ChatGPT doesn’t mean you rank well in Gemini or Perplexity. Platform-specific blind spots can cost you a significant share of total AI-driven traffic, and you won’t see it unless you’re tracking cross-platform.
Data without competitive benchmarks. A 15% mention rate is excellent in a fragmented local services market. It’s a failure in consolidated software categories. Without competitive Share of Voice data, your visibility numbers are directional at best.
That last point is where most teams get stuck.
Topify’s Competitor Monitoring tracks how competitors perform across the same prompt set, so your visibility score has context rather than just magnitude. You stop guessing whether 20% is good and start knowing exactly who you’re behind and why.
From AI Optimization Metrics to Real Search Visibility Actions
Data without a feedback loop is just expensive reporting.
Low citation rate on owned content? Rewrite with an answer-first format. Open each section with a direct 2–4 sentence answer to the question posed in the heading. Research shows this approach increases citation likelihood by roughly 40%.
Competitor getting cited via a third-party blog you’re not on? Don’t rewrite your website. Prioritize digital PR outreach to that specific publication. AI models build trust through consensus signals from authoritative external sources. 96% of AI Overview citations come from high E-E-A-T domains, including industry journals, Wikipedia, and authoritative review platforms. The leverage is in external authority, not self-published content.
Low technical visibility despite strong content? Check your schema. Valid Organization, Product, and FAQPage schema makes a brand 3.5x more likely to be cited by AI. Also verify your robots.txt explicitly allows GPTBot and ClaudeBot to crawl your site.
Declining freshness on key pages? A content refresh alone can boost citation frequency by 28%. AI models weight recency as a trust signal, especially for rapidly evolving categories.
Topify’s Source Analysis surfaces exactly which domains AI platforms cite for your target topics. Your content team gets a prioritized outreach list instead of a blank page.
That’s the difference between a tracking system and an optimization engine.
A 10-Point Checklist for Your AI Recommendation Tracking Setup
Score yourself before investing in prompt coverage expansion. Below 6 out of 10, fix the infrastructure first.
- Crawler access: robots.txt explicitly allows GPTBot, Google-Extended, and ClaudeBot
- Entity verification: consistent Name, Address, Phone (NAP) data across all directories, plus a clear About page with leadership bios
- Prompt diversity: at least 20 prompts covering branded, category, and comparison intents
- Platform breadth: tracking live across ChatGPT, Gemini, and Perplexity at minimum
- Sampling stability: weekly tracking cadence to account for model stochasticity
- Metric integration: Mention Rate, Position, Sentiment, and Citation Rate tracked as a unified visibility score
- Schema deployment: valid Organization, Product, and FAQPage schema on all key landing pages
- Source intelligence: top 10 third-party domains cited in your category identified and monitored
- Revenue attribution: AI visibility data connected to GA4 referral traffic and branded search volume
- Hallucination oversight: a review workflow to catch and correct AI misrepresentations of your brand
Conclusion
65% of searches now end without a website visit. That traffic isn’t disappearing. It’s being absorbed by the AI model that answered the question first.
The brands that win in this environment aren’t the ones with the highest keyword rankings. They’re the ones with the highest model confidence. And model confidence is measurable. Track the five core metrics. Build a real prompt library. Automate the execution. Use the data to act, not just to report.
If you want to see where your brand stands today, get started with Topify and run that entire workflow from a single dashboard.
FAQ
Q: What is an AI recommendation tracking strategy?
A: It’s a systematic approach to monitoring how generative AI models perceive and recommend your brand. Unlike traditional SEO, which tracks where you appear in a list, an AI recommendation tracking strategy tracks whether a language model selects and synthesizes your brand into its answer when users ask questions about your product category or use case.
Q: How do I measure an AI recommendation tracking strategy?
A: Performance is measured through a composite of five core metrics: Mention Rate (how often you appear), Position (where you appear in the response), Sentiment Score (the tone used), Citation Rate (how often your domain is linked), and Prompt Coverage (how many relevant queries trigger a brand mention). These metrics should be benchmarked against competitors and tracked over time.
Q: What are the best tools for AI recommendation tracking strategy?
A: Topify is built specifically for this. It tracks all major AI platforms with seven GEO metrics, automates prompt monitoring, and includes one-click optimization execution. For teams exploring basic AI Overview tracking, SE Ranking and Authoritas offer entry-level options. Full-scale cross-platform monitoring typically requires a dedicated platform with multi-engine coverage.
Q: How much does an AI recommendation tracking strategy cost?
A: Topify’s Basic plan starts at $99/month and includes 100 prompts, 9,000 AI answer analyses, and tracking across ChatGPT, Perplexity, and AI Overviews. The Pro plan is $199/month for 250 prompts. Enterprise plans start at $499/month with dedicated account management. Across the broader market, basic monitoring tools range from $29–99/month, while enterprise-grade platforms typically run $800–2,500/month.

