
You asked ChatGPT to recommend a project management tool for remote teams. It returned three names. Yours wasn’t one of them.
That’s not a content gap. That’s not a keyword problem. That’s the result of how agentic AI decides which brands are worth recommending — and most marketing teams still don’t have a system to measure it.
Agentic AI Doesn’t Just Search. It Decides.
Traditional search engines work like librarians. They index content, match keywords, and hand you a list. You do the evaluation.
Agentic AI works differently. It enters a multi-step reasoning loop: it breaks down your query into sub-tasks, pulls data from multiple sources, evaluates the evidence for confidence, and synthesizes a single answer. There’s no list of links for the user to sort through. There’s just a recommendation.
That shift matters enormously for brands. When a user asks, “Which CRM is best for a mid-market manufacturing firm?” an agentic system doesn’t return 10 results — it returns one or two names it’s judged to be most credible. If your brand isn’t part of that judgment, you don’t get a fallback position. You’re simply not in the answer.
The gap between traditional search and agentic AI isn’t about design preferences. It’s architectural.
| Dimension | Traditional Search | Agentic AI |
|---|---|---|
| Role | Information indexer | Research analyst |
| Logic | Keyword matching | Semantic reasoning |
| Output | List of links | Synthesized answer |
| Retrieval | Single-pass indexing | Iterative sense-decide-act loop |
| User action | Clicks to decide | Agent has already decided |
The 3 Signals Agentic AI Uses When Evaluating Your Brand
Agentic AI doesn’t have preferences. It follows patterns. And those patterns are shaped by three measurable signals.
Mention Frequency. LLMs are trained on statistical density. If your brand appears frequently in high-quality, relevant discussions — Reddit threads, industry journals, news coverage — the model builds a strong semantic link between your name and your category. Crucially, unlinked mentions carry nearly as much weight as linked ones. Unlike Google’s PageRank logic, LLMs analyze patterns across the whole web, not just backlink graphs.
Sentiment Context. Being mentioned isn’t enough. The AI classifies the tone surrounding each mention. A positive recommendation scores high; a negative or ambiguous mention can effectively cancel visibility gains. If your brand’s historical footprint includes unresolved customer complaints or controversy on forums, the model will either deprioritize you or add disclaimers. Your reputation isn’t just a brand metric — it’s a ranking factor.
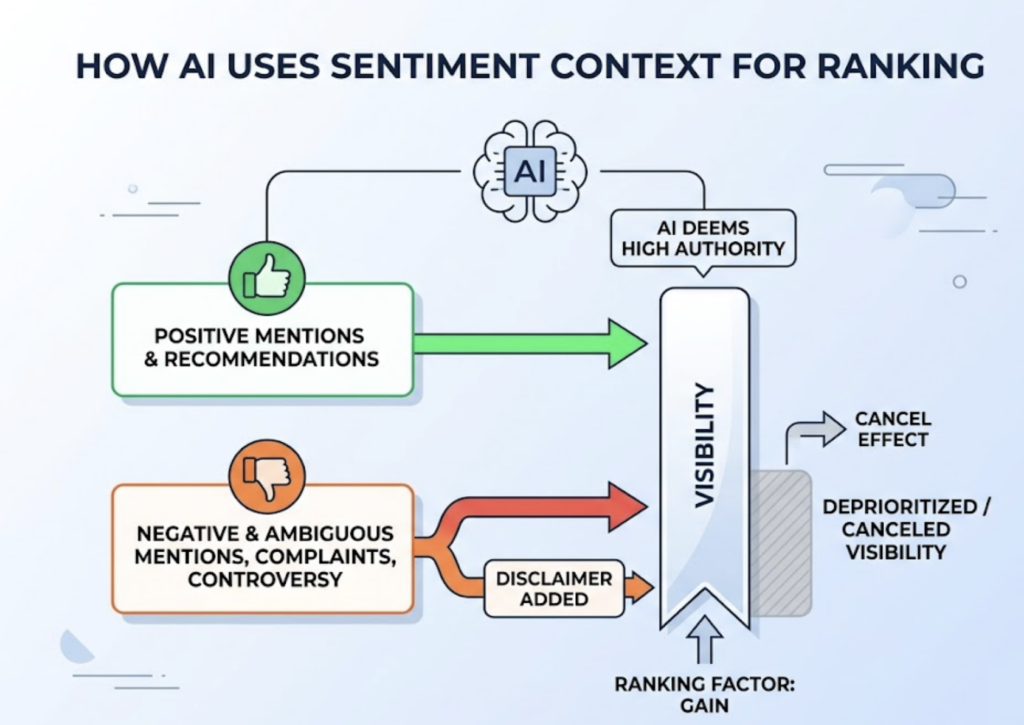
Source Authority. Agentic systems minimize hallucination by grounding responses in trusted sources. Research shows brands are 6.5 times more likely to be cited through third-party platforms like G2, Wikipedia, or reputable industry publications than through their own websites. If your narrative only lives on your own domain, the AI assigns it a low confidence score.
These three signals compound. High frequency + positive sentiment + authoritative third-party coverage = a brand the AI recommends confidently. Miss one, and you’re in the “sometimes mentioned” category. Miss two, and you’re invisible.
Why Strong Google Rankings Don’t Guarantee AI Visibility
This is the assumption that catches most teams off guard.
An Ahrefs analysis of 1.9 million AI citations found that only 12% of those citations matched Google’s Top 10 results for the same query. More striking: 80% of AI citations don’t rank anywhere on Google for the original search term.
The systems prioritize different things. Google weights backlinks, page speed, and keyword placement. Agentic AI weights what researchers have formalized as “Semantic Completeness” and “Extractability” — basically, can the AI parse your content quickly and confidently?
Here’s a real pattern that illustrates this: a law firm ranked #1 on Google for “personal injury lawyer Miami” — a position built on a DA 80 domain and decades of link-building. In ChatGPT, it received zero mentions. Smaller boutique firms with Reddit discussions and “Best of” mentions on niche legal blogs got recommended instead. Their content was structured for AI extraction; the high-DA firm’s content was structured for crawlers.
| Signal | Agentic AI | |
|---|---|---|
| Primary currency | Backlinks & domain authority | Mentions & digital consensus |
| Content structure | Long-form narrative | Extractable chunks, answer-first |
| Logic | Lexical strings | Semantic entities |
| Outcome | Click-through traffic | Citation & recommendation |
Agentic AI is computationally “lazy” in a specific way: it favors sources that deliver a clean 40-60 word definition or fact over sources that require it to synthesize across paragraphs. If your content makes the model work harder to extract an answer, it’ll pull from a source that doesn’t.
A Step-by-Step Look at How Brand Visibility Tracking Actually Works
Because AI responses are probabilistic — they vary by session, user context, and model version — static audits don’t work. You need continuous probability mapping. Here’s the methodology that holds up.
Step 1: Define the prompts AI users actually ask.
Don’t track your brand name. That’s a bottom-funnel vanity metric. Real discoverability happens when you appear in unbranded, category-level queries. Build a prompt library across three types:
- Category prompts: “What are the best [category] tools for remote teams?”
- Comparison prompts: “Tool A vs. Tool B for mid-market security”
- Problem-solution prompts: “How to reduce infrastructure costs for a SaaS startup”
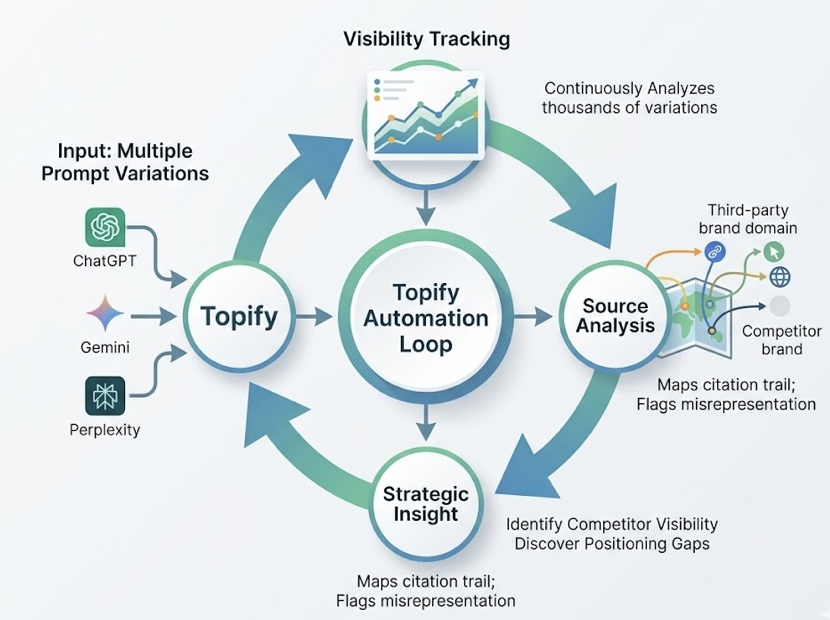
Step 2: Run those prompts across multiple AI platforms.
ChatGPT, Gemini, and Perplexity don’t agree. There’s only an 11% overlap between sources cited by ChatGPT and Perplexity for the same query. Each platform has its own retrieval bias: ChatGPT favors authoritative encyclopedic sources; Perplexity rewards freshness and community validation; Gemini leans on Google’s Knowledge Graph. A brand invisible on one may be prominent on another.
Step 3: Measure visibility rate, position, and sentiment per platform.
A single check is a data point. Running the same prompt 100 times gives you a confidence interval. Your brand might appear in 34% of ChatGPT responses but 61% of Perplexity responses. That’s a strategic insight, not a coincidence.
Three numbers matter here: Visibility Rate (raw probability of being mentioned), Position in Response (brands in the first three positions carry 4-5x more recall weight than later mentions), and Sentiment Score (is the AI recommending you or just listing you?).
Step 4: Identify the sources the AI is citing.
Reverse-engineer the footnotes. Find the exact URLs the AI’s retrieval layer treats as authoritative for your category. If a competitor is winning citations because of a specific Reddit thread or a pricing guide on a third-party review site, that’s your next content target.
Step 5: Close the gap with targeted actions.
If your Visibility Rate is low but your Google ranking is strong, the problem is extractability. Restructure your content with clear headings, answer-first architecture, and structured data tables. If visibility is low because of missing third-party coverage, build it: guest contributions, G2 profiles, community presence on the platforms the AI trusts.
Topify automates this entire loop. Its Visibility Tracking continuously analyzes thousands of prompt variations across ChatGPT, Gemini, and Perplexity simultaneously — without manual testing. The Source Analysis feature maps the citation trail automatically, identifying which third-party domains are carrying competitor visibility and flagging positioning gaps where your brand is being misrepresented or underrepresented.
The Metrics That Actually Matter in an Agentic AI World
Most marketing dashboards weren’t built for this environment. Clicks, impressions, and bounce rates don’t capture whether an AI recommended you or ignored you.
| Metric | What It Measures | Priority |
|---|---|---|
| AI Visibility Rate | % of relevant prompts where your brand appears | ⭐⭐⭐ High |
| Position in Response | 1st mention vs. 4th — predicts decision influence | ⭐⭐⭐ High |
| Source Citation Rate | How often AI cites your domain vs. third-party sources | ⭐⭐⭐ High |
| Sentiment Score | Positive / neutral / negative mention context | ⭐⭐ Medium |
| Branded Search Lift | Increase in branded searches after AI-driven discovery | ⭐⭐ Medium |
| ❌ Keyword Ranking | Traditional Google position | Low |
Keyword ranking isn’t worthless. It still supports bottom-funnel conversions when someone’s looking for your checkout page. But it’s a poor predictor of whether you’ll make it into the AI’s initial recommendation set.
That’s the metric shift the “Answer Economy” requires.
What Optimization Looks Like When You Have the Data
The data tells you which problem you actually have. Two scenarios illustrate this clearly.
High Sentiment, Low Visibility. Your Sentiment Score is strong — the AI describes your brand as “innovative” and “reliable” — but your Visibility Rate sits at 8%. The diagnosis: the AI likes you, but can’t find enough evidence across its retrieval sources to mention you consistently. It’s an exposure gap, not a reputation gap. The fix is building third-party consensus: guest mentions on industry blogs, updated G2 reviews, presence in the Reddit communities the AI’s retrieval layer trusts.
High Visibility, Low Position. Your brand appears in 70% of relevant AI answers but consistently lands 3rd or 4th in the list. The AI knows you exist but treats you as a secondary option. To move up, you need what practitioners call “Information Gain” — proprietary research, case studies with quantified outcomes, or named frameworks that give the AI a definitive data point it can quote as ground truth.
The operational challenge is what happens after the diagnosis. Most teams stall here because executing content changes across multiple platforms and formats takes time. Topify’s One-Click Agent Execution addresses this directly: once a visibility gap is detected, the platform’s AI agent analyzes content gaps against competitor citations, drafts GEO-optimized content including schema markup and data tables, and deploys directly to your CMS. Brands using this execution model report a 920% lift in AI-driven traffic compared to teams relying on manual optimization cycles.
The sense-decide-act loop isn’t a metaphor. It’s how optimization actually runs in 2026.
Conclusion
Agentic AI doesn’t recommend brands because they have good products. It recommends them because they’re the most “legible” and “verified” solutions within its reasoning space.
That means visibility is measurable. It’s not luck, and it’s not a black box. Mention frequency, sentiment context, and source authority follow patterns you can track, benchmark, and close gaps against.
The brands that figure this out first aren’t just winning AI recommendations. They’re setting the consensus that everyone else gets measured against.
Frequently Asked Questions
What is agentic AI in the context of brand visibility? Agentic AI refers to AI systems that autonomously plan, retrieve information, and synthesize answers — rather than returning a list of links. For brands, this means the AI is actively deciding whether to recommend you based on your presence in its training data and retrieval sources.
How is AI brand visibility different from traditional SEO rankings? Traditional SEO optimizes for crawler-readable content and backlink authority. AI visibility depends on mention frequency, sentiment context, and third-party source coverage. Research shows only 12% of AI citations match Google’s Top 10 results for the same query — the two systems are largely measuring different things.
Which AI platforms should I track my brand on? At minimum: ChatGPT, Perplexity, and Gemini. Each uses different retrieval logic and cites different sources. There’s only 11% source overlap between ChatGPT and Perplexity responses — tracking just one gives you an incomplete picture.
How often should I run brand visibility tracking? AI responses are probabilistic and shift with model updates, so continuous monitoring beats periodic audits. Running the same prompts 100 times across platforms gives you a statistically reliable confidence interval rather than a single data point.

